Im Zuge eines Vortrags zur grundlegenden Vermittlung von Datenbankwissen wurden die Teilnehmer der Spring School mit der Aufgabe und Lösung konfrontiert, wie eine simple Datenbank eines Buchausleihsystems für eine Bibliothek aufzubauen wäre. Die Frage war dabei welche Variablen erhoben werden müssen, wie diese organisiert und in Beziehung gesetzt werden sollen.
Grundlage
Grundlegend besteht eine Datenbank aus mehreren Tabellen, die zueinander in Beziehung stehen. Jede Tabelle erfasst dabei Variablen zu einem Datentyp. Ziel ist es dabei möglichst wenige Redundanzen (also Doppeleinträge) zu erzeugen. Eine Datenbank stellt dabei immer eine Abstraktion dar, die Informationen für die Analyse aufbereitet, selbst jedoch erst durch die Interpretation des Forschenden aussagekräftig wird.
Die Lösung für das Buchungssystem war dabei eine Tabelle zu den Personendaten (Bibliotheksausweisnummer, Name, Geburtstag, Alter etc.) eine Tabelle zu den Büchern (Titel, Autor, Verlag etc.) und eine Tabelle zu den Buchungen (Buchungsnummer, Buch ID, Personen ID), welche die beiden anderen Tabellen zueinander in Bezug setzt.
Problemstellung
Für meine eigene Forschung habe ich derzeit eine einfache Tabelle als „Datenbank“ zu den mir beforschten Hexenprozessakten angelegt. Diese konzentriert verschiedene Informationen wie Namen der Angeklagten, Ort, Datum, Urteil, Folter, biografische Informationen etc. Die Reflexion über den Vortrag und das Beispiel des Buchungssystems hat mich dazu veranlasst, diese Struktur grundlegend zu überdenken. Ziel ist es dabei eine wachsende Datenbank für den eigenen Forschungsbedarf anzulegen, in denen die Informationen zu den Hexenprozessen systematisch erfasst werden.
Konzeption
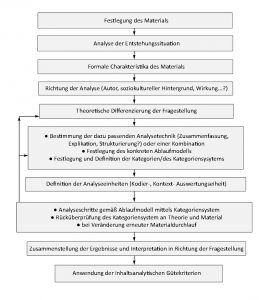
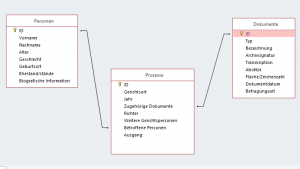
Ausgehend von der dreigliedrigen Aufteilung des Buchungssystems habe ich dieses in Beziehung zu meinem Material gesetzt. Parallel zu den Personendaten des Bibliothekssystems schien es sinnvoll die Daten der Prozessopfer in einer eigenen Tabelle zu erfassen (Namen, Alter, Geburtsort, Biografie etc.). Der Tabelle zu den Büchern entsprach dabei eine Tabelle zu den Prozessakten/Dokumenten (Dokumentname, Typ, Datum, Quellangabe). Die Parallele zur „Buchung“ stellte abschließend der Prozess dar (Prozessdatum, Ort, Richter, Urteil/Ausgang etc.). In Microsoft Access sah die abschließende Beziehung zwischen den Tabellen dabei in etwa wie folgt aus:
Offene Problemstellung
Diese theoretisch sehr einfache Konzeption stieß jedoch in der Praxis auf ein spezifisches Problem, die Definition des „Prozesses“. Während Personen und Dokumente sehr eindeutig zu definieren sind, erweist sich die Definition des juristischen Prozesses als sehr schwierig.
Nimmt man an, ein Prozess sei eine Einheit aus Anklage-Verhör-Urteil, so stößt man auf das Problem, der fragmentarischen Überlieferung. Wie ist beispielsweise ein Dokument zu fassen, das den Foltertod einer Angeklagten erfasst (wie in Hainburg 1617/18 Mahrech Legeschürzin)? Offenbar geht dem ein juristischer Prozess voraus, weder Urteil, noch Anklage, noch Verhör oder Richter sind aber bekannt. Selbst wenn man hier den Rahmen weit spannt und feststellt, jeder Prozess der zumindest durch Urteil, Verhör oder Anklage greifbar wird, wird als einzelner Eintrag erfasst, stellt sich noch ein weiteres Problem.
Sollen Einzel- oder Sammelprozesse erfasst werden? Sind beispielsweise die 19 in Hainburg von November 1617 bis April 1618 zu Tode gekommenen Frauen einem gemeinsamen Prozess zuzuordnen? Oder handelt es sich in der Erfassung in der Datenbank um 19 Einträge? Die Prozesse werden in drei Urteilen behandelt, also könnte man diesen Prozess auch als drei Prozesse erfassen. Was ist jedoch mit den 18 in Rostock 1584 hingerichteten Personen? Sie verbindet teilweise ein gleicher Hinrichtungstag, ob die Prozesse getrennt oder gemeinsam geführt wurden, lässt sich nicht feststellen. Wo ist hier die Grenze zwischen unerwünschter Redundanz und übermäßiger (möglicherweise künstlicher) Zusammenfassung zu ziehen?
Diese Problemstellung konnte bisher noch nicht befriedigend geklärt werden, verdeutlicht aber wiederum, dass eine Datenbank eine Abstraktion vom Material darstellt, die keineswegs „neutral“ ist und genau reflektiert und begründet werden sollte.