Was ist LDA Toolkit?
Das LDA-Toolkit ist eine Metasoftware für quantitative Korpuslinguistik, die unter sich verschiedene Tools zur Analyse kleinerer und größerer Sprachdatensammlungen (Korpora) versammelt. Sie wurde vom Sprachwissenschaftler Friedemann Vogel programmiert und wird bisher stetig weiterentwickelt. Das Toolkit dient insbesondere vergleichenden und kontrastiven Analysen durch die Einbindung zweier Korpora, die über sprachstatistische Analysen miteinander verglichen und in Beziehung gesetzt werden können. Alle Teile des Toolkits stehen als Freeware unter der Creatice Commons License für nicht-kommerzielle Zwecke zur Verfügung. Das Toolkit kann auf der Webseite von Friedemann Vogel kostenlos heruntergeladen werden. Wir danken an dieser Stelle Friedemann Vogel für die Bereitstellung.
Vorteile:
- „kostenlos“ (s.o.) und lokal unter Windows installierbar
- verschiedenste Tools bis hin zur Aufbereitung der Visualisierung von Ergebnissen in einer Software. Dadurch ist kein Wechsel zwischen unterschiedlich arbeitetenden Programmen notwendig
- Aufbereitung der Daten mit syntaktischen-morphologischen Informationen notwendig, womit aber neben semantischen auch konstruktionsgrammtische und syntaktisch-morphologische Analysen usw. möglich sind (kann aber auch Nachteil sein, s.u.).
- Workflow-„Baum“ leitet durch die einzlenen Tools und damit durch die Analyse
- Fokus auf quantitative Analyse (kann aber auch Nachteil sein, s.u.)
Nachteile:
- Einarbeitungszeit
- Aufbereitung der Daten mit syntaktisch-morphologischen Informationen notwendig. Dafür bietet Friedemann Vogel das Tool Corpustransfer an. Alternativ kann auch eine Software zur syntaktisch-morphologischen Aufbereitung der Daten, die auch dem Tool Corpustransfer als Basis dient, verwendet werden.
- Kein Möglichkeit der qualitativen Aufbereitung durch individuelle Annotationen.
Nutzungsszenario 1: Der Vergleich von Korpora
Material: zwei Spezialkorpora
Fragestellung: Sie nutzen unterschiedliche Korpora? Weil: Sie haben eine semantisch-pragmatische, diskurslinguistische oder (konstruktions)grammtische usw. Fragestellung und wollen bspw. Korpora unterschiedlicher Zeiträume, unterschiedlicher Akteure, Gruppen, Parteien usw. vergleichen und kontrastieren. Um es einfach zu gestalten, nehmen wir eine simple Fragestellung, die insbesondere die lexikalische Ebene in den Blick nimmt: Wie wird die Einheit Text in der Linguistik und wie im allgemeinen Sprachgebrauch bzw. Alltagssprachgebrauch und Vermittlungssprachgebrauch auf basalerem Niveau (z. B. in Artikeln zu Wikipedia, nicht-linguistischen Beschreibungen) konzeptualisiert? Als Grundlage dienen die Texte, die im Paderborner Textanalyseportal TAP zur Unterstützung der Lehre im Bereich der Textlinguistik als Lehrvideos weiterverarbeitet wurden. Sie bieten einen umfassenden fachlichen Überblick über den Themenbereich und stützen sich auf diverse fachliche Literatur zur Textanalyse und bilden das fachliche Korpus „TAP“. Das zweite Korpus reichern wir mit unterschiedlichsten Texten an wie Definitionen zu „Text“ aus nicht-linguistischen Quellen und Texten aus öffentlichen Korpora des DWDS, in denen das Wort Text verwendet wird. Wir nennen dieses Korpus „Alltagssprache“. Es liegt auf der Hand, dass damit ein konzeptuell bunt zusammengewürfeltes Korpus entsteht z. B. mit Bezug auf unterschiedlichste Textsorten, unterschiedlichste Textproduzenten mit unterschiedlichsten Wissenshintergründen. Die Korpusbildung dient jedoch nur der Übung und Veranschaulichung.
Vorgehen:
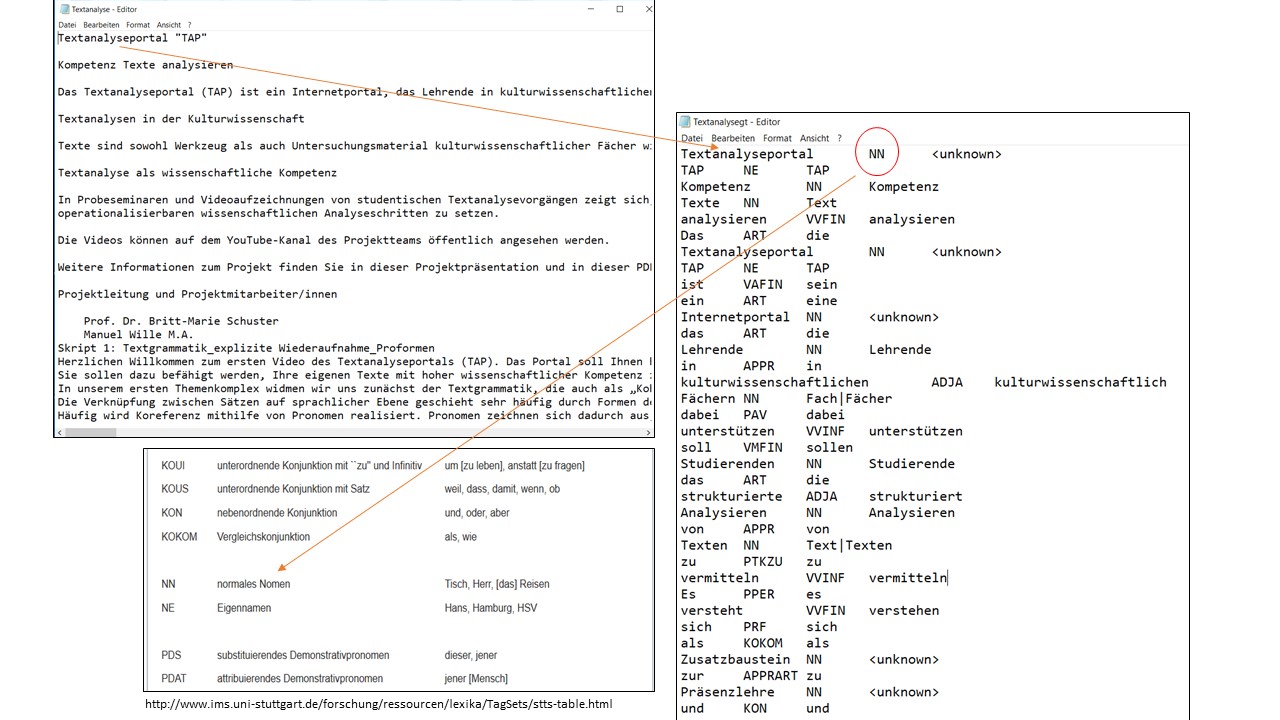
Die Analysesoftware LDA-Toolkit bietet viele ausgefeilte Möglichkeiten der Analyse, weshalb auch die Texte entsprechend vorbereitet werden müssen. Eine dieser Möglichkeiten ist, auf syntaktisch-morphologische Kategorien der Korpuselemente zurückgreifen zu können, um bspw. syntaktische Muster innerhalb des Korpus erkennen und bestimmen zu können. Hierfür müssen die beiden Korpora (Korpus TAP und Korpus Alltagssprache) jeweils mit diesen Informationen angereichert werden. Dafür werden .txt-Dateien verwendet, die in jedem Betreibssystem mit einem Editor erzeugt werden können. Diese .txt-Dateien mit den Texten des jeweiligen Korpus werden, bevor die Arbeit mit dem LDA-Toolkit losgeht, in Programmen wie Treetagger oder Corpustransfer mit syntaktisch-morphologischen Informationen aufbereitet. Der Text wird dabei in einzelne, durch Leerzeichen oder Interpunktion abgegrenzte Zeichenkomplexe zerlegt. Den Zeichenkomplexen werden Wortarteninformationen und Stammformen zugeordnet. Diesen Vorgang nennt man POS-Tagging. Im Bild untene sieht man die Arbeit mit dem Treetagger, für den zuvor die deutsche Sprachdatei im Treetagger-Ordner abgelegt wurde. Alle Einstellungen bleiben nach dem Start des Treetaggers so wie sie sind. Ausgewählt wurde lediglich die deutsche Sprachdatei. Sie wählen die Quell-.txt-Datei und die text-Datei aus, in die das getaggte Korpus überführt werden soll und klicken auf „Run“.
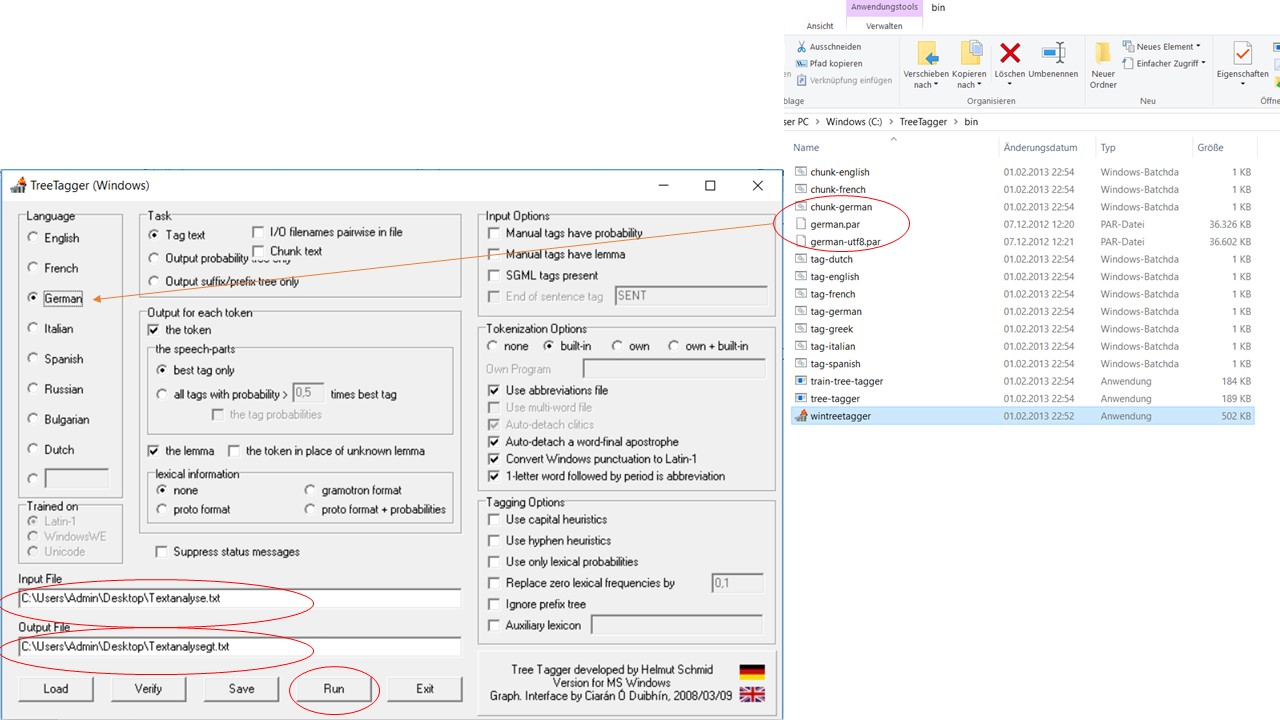
Die Zuordnung basiert auf dem dem Stuttgard-Tübingen-Tagset und ist sehr zuverlässig. In unserem Fall wird Textanalyseportal mit NN (=Normales Nomen) erkannt, wobei es in diesem Kontext sogar ein Eigenename ist, der jedoch von einem Kompositum mit gebräuchlichen Einheiten ausgeht, weshalb hier nicht wie bei TAP mit NE (=Eigenname) annotiert wurde. Änderungswünsche können aber vor dem Import in das Toolkit auch direkt in der annotierten .txt-Datei umgesetzt werden. Als Handreichung kann dafür das benannte Tagset dienen.
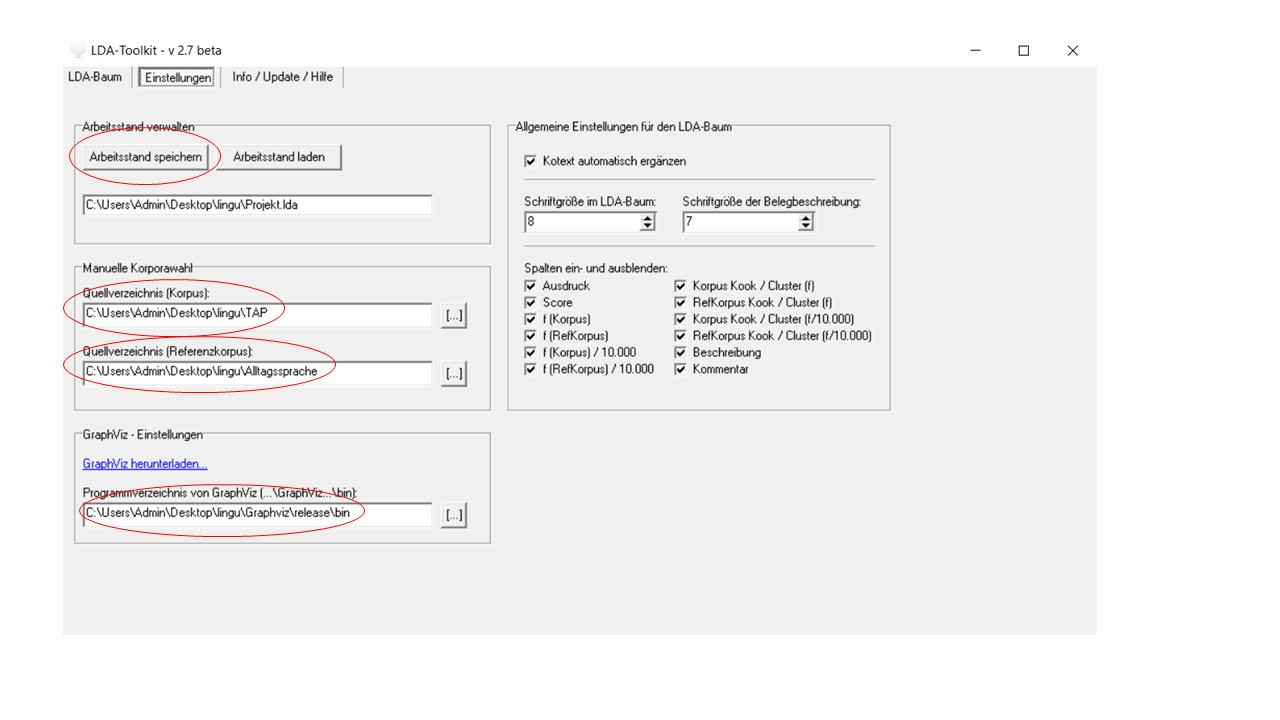
Wurden beide Korpora getaggt, können sie in das Toolkit über den Registerreiter „Einstellungen“ geladen werden. Das Toolkit erlaubt das Abspeichern des Arbeitsstandes, weshalb dieser Vorgang nicht immer wiederholt werden muss.
Zusätzlich lassen sich über das Toolkit graphische Darstellungen der nummerischen Ergebnisse erzeugen. Dafür ist eine Schnittstelle zur Software GraphViz integriert. Die Software muss über den Link, der im Programm hinterlegt ist, heruntergeladen werden und das Verzeichnis von GraphViz bis zum Ordner „\bin“ muss im Toolkit angegeben werden.
Nun kann man über den Registerreiter „LDA-Baum“ zur Analyseoberfläche wechseln. Vor der Analyse ist es notwenig, über „Alle bestimmen“ die Token und Lemmata der beiden Korpora zu bestimmen. Das gibt auch schon einen Überblick über die quantitativen Verhältnisse beider Korpora.
Unter „LDA-Baum“ findet man alle Analysemöglichkeiten. Neben dem großen Analysefenster links hält das Toolit rechts eine Reihe an Registerreitern bereit mit verschiedenen Analysemöglichkeiten. Sinnvoll ist der Registerreiter „ToDo“ gerade für Neulinge. Friedemann Vogel bietet hier einen kompletten Workflow, der durch die Analysemöglichkeiten der Korpuslinguistik bezogen auf das Toolkit führt. Die Bedeutung der einzelnen Spalten des linken Analysefensters sind in der Dokumentation zum Toolkit aufgeführt. Die Dokumentation befindet sich nach der Installation im Verzeichnis der Programme.
Keywordanalyse
Mit der Keywordanalyse werden Schlüsselwörter herausgefunden, deren Werte als absolute oder relative (z. B. relativ zur Gesamtgröße des Korpus, weitere Informationen zur absoluten, relativen Häufigkeit und Wahrscheinlichkeitsverteilung finden Sie unter Links.) angegeben werden. Schon an dieser Stelle können POS-Annotation genutzt werden, um erste Eingrenzungungen zu machen. Hier wurde die Schlüsselwortanalyse auf substantivische Einheiten (NN, NE) beschränkt, um zu schauen, ob es eine spezielle (nominale) Fachterminologie gibt, die im alltagssprachlichen Gebrauch oder in alltagssprachlichen Definitionen und Auffassungen über die Einheit Text nicht zu finden sind. Die markierten Einheiten zeigen nur im fachlichen Korpus vorhandene Ausdrücke, die zu einer linguistischen Definition von Text herangezogen werden. Im Korpus Alltagssprache sind diese nicht zu finden. Eine Stärke des Toolkit ist der Vergleich von Korpora. Die Ergebnissen zeigen deshalb nicht nur, dass bestimmte Einheiten häufig und relativ häufig vorkommen, sondern auch, ob sie im Quellkorpus (hier: TAP) signifikant (also im Vergleich zum Referenzkorpus, hier: Alltagssprache) vorkommen. Interessant erscheint in dieser Ergebnisliste der Ausdruck Satz, der in beiden Korpora vorkommt, aber anscheinend im Quellkorpus öfter. Satz scheint vorerst konstitutiv für das Verständnis von Text im Fachlichen wie im Alltagssprachlichen.


Eine weitere Stärke des Toolkit ist die Weiterverarbeitung der Ergebnisse im Analysefenster. Die einzelnen Ergebnisse werden dort gespeichert (hier: vier Keywordanalysen), können in der Baum-Suche oben durchsucht und gefiltert werden, an weitere Analysemöglichkeiten wie der Keywords-in-Kontext-Analyse durch Markierung im Verzeichnisbaum weitergegeben werden oder die Analyseergebnisse können durch Rechtsklick auf den obersten Knoten (hier jeweils Keywords) exportiert werden. Über einen Doppelklick kann jeder Verzeichnisbaum oder einzelne Datensätze des Baums mit Kommentaren versehen werden. In allen Registerreitern können die Analyse filternde neue Ausdrücke oder Ausdrücke aus dem Verzeichnisbaum als Muster (Lemmata) oder als flektierte Wortformen (Token) verwendet bzw. übernommen werden. Zudem können die Suchergebnisse entsprechend auf Lemmata oder Token erweitert oder eingeschränkt werden.
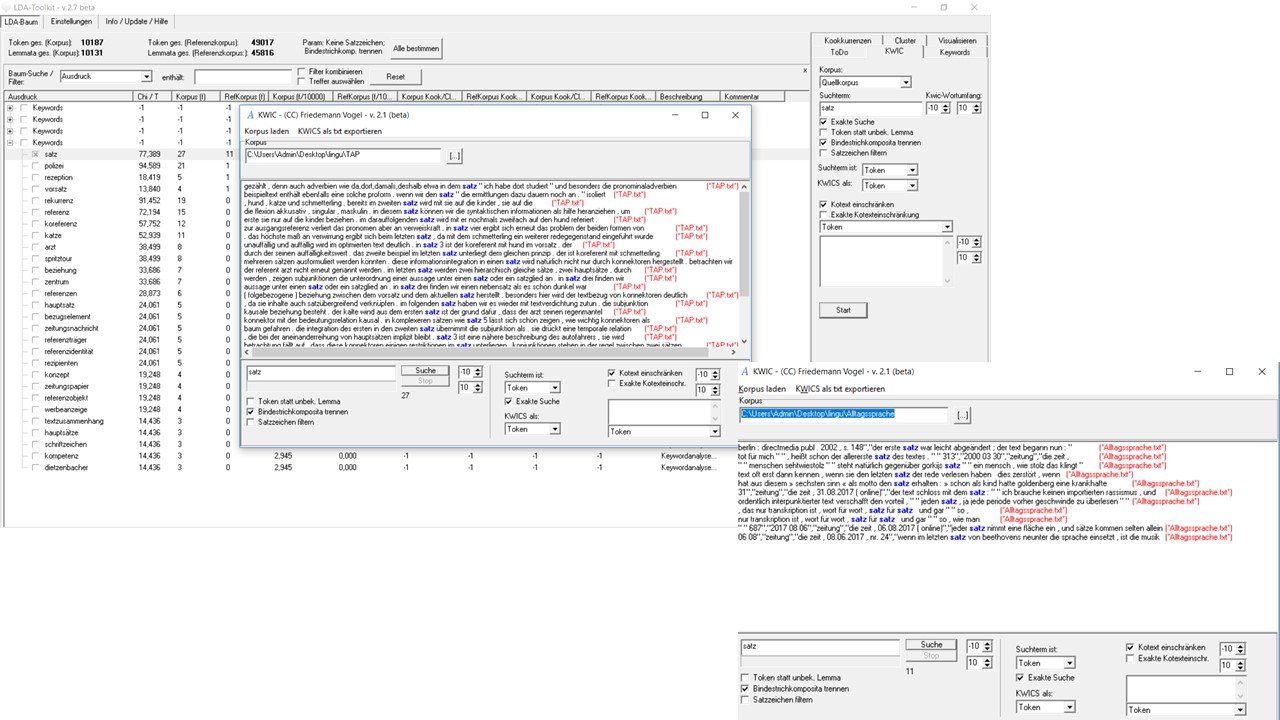
KWIC – Keywords-in-Kontext
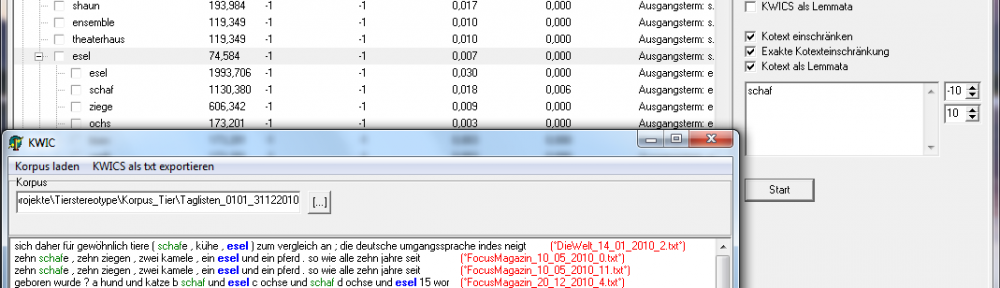
Ein Blick in die Belege zeigt mehr über das Vorkommen des Ausdrucks Satz, der hier ausgewählt wurde. Die KWIC-Ansicht erlaubt den Einblick in den Kontext von Ausdrücken und Ausdruckskomplexen bzw. Clustern. Sie beschränkt sich jedoch nur auf ein Korpus, weshalb neben anderen Einstellungen jeweils ausgewählt werden muss, welches Korpus hier durchsucht werden soll. Neu hinzu kommt die Funktion, nicht nur die Suchergebnisse aus dem Baum zu übernehmen, sondern auch die Suche auf einzelne Knoten festzulegen, indem diese als Kotext für die Suche definiert werden. Diese Einstellung ist auch bei der Analyse von Kookkurrenzen möglich.
Im fachlichen Quellkorpus ist zu erkennen, dass in den Belegstellen immer wieder auf die Beziehung von Einheiten in verschiedenen Sätzen im Sinne einer transphrastischen Auffassung von Text, in der solche Einheiten satzübergreifend und satzverbindend wirken, während im Referenzkorpus Satz immer wieder als Orientierungsgröße im Text konzeptualisiert wird.
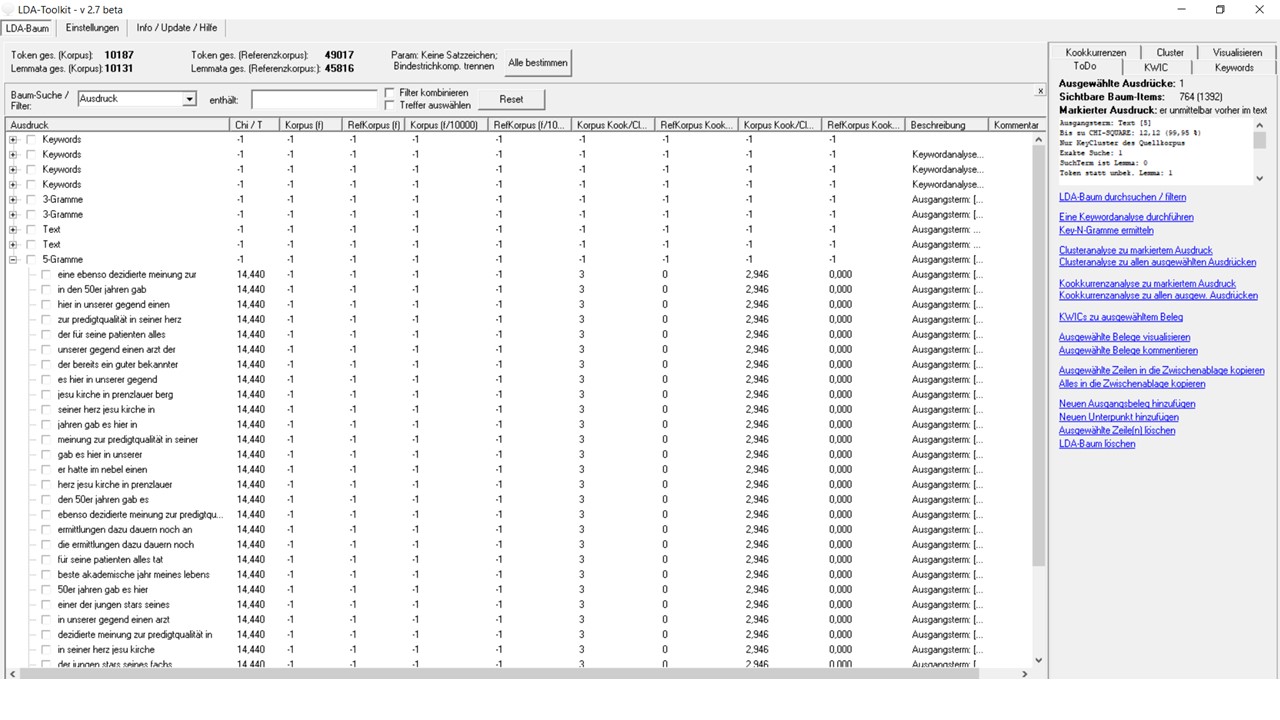
Cluster-Analyse
Durch die Analyse von Clustern oder N-Grammen werden im Korpus verfestigte Mehrwortverbindung ausgehend von einem Ausgangsterm (Cluster) oder als nicht näher zuvor determinierte Mehrwortverbindungen gesucht. Cluster mit Ausgangsterm können mit der Einstellung POS-Gramme auf das grammtische Muster, welches hinter der Mehrworteinheit steht, hin eingeschränkt werden. Das Ergebnis sind Mehrwortkomplexe, deren Größe zuvor festgelegt werden kann und die immer wieder in dieser Verbindung vorkommen. Die Analyse von Clustern oder N-Grammen ist immer ein Abgleich beider Korpora, weshalb hier die Siginfianz der Mehrworteinheit oder des grammtischen Musters in Abgleich mit dem Referenzkorpus im Vordergrund steht. In unserem Fakll sind jedoch keine analytisch interessanten Cluster oder N-Gramme auszumachen.
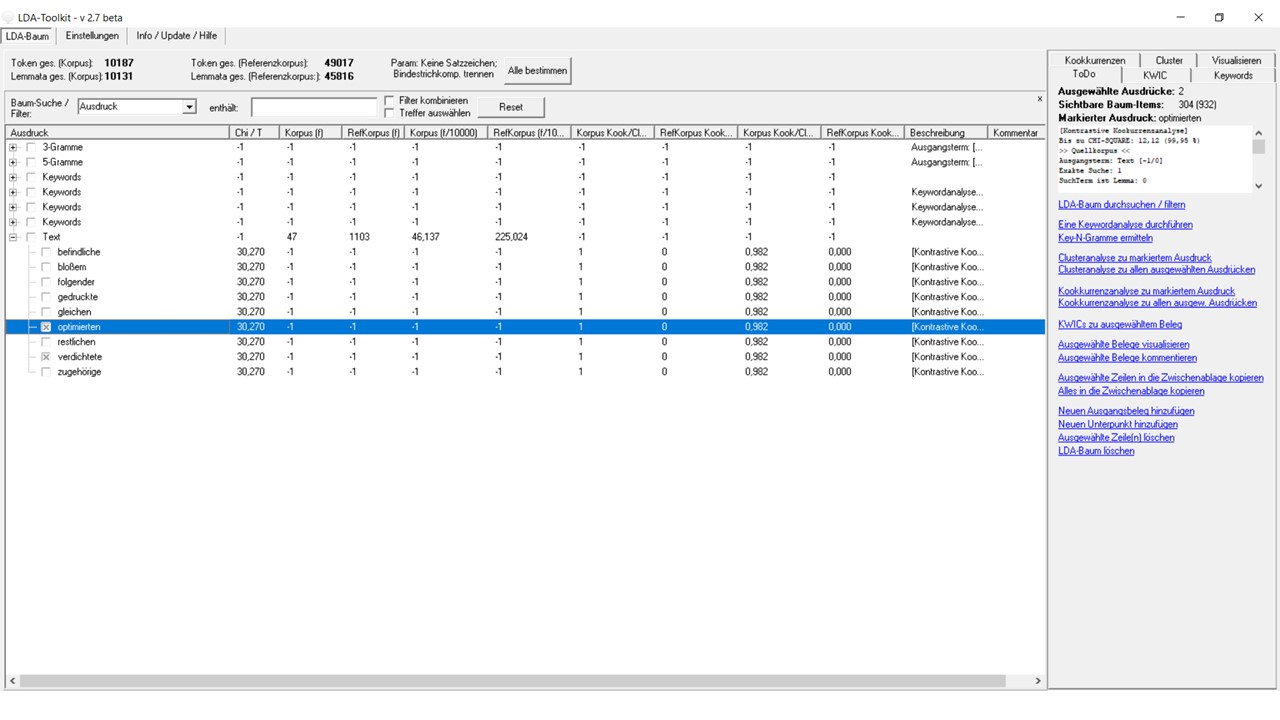
Analyse von Kookkurrenzen
Kookkurrenzen als linke und rechte „Mitspieler“ von Wörtern im Korpus werden dann interessant, wenn ihre Signifikanz zu anderen Kookkurenzen in den Blick genommen wird. Welche Reichweite solche Kookkurenzen links und rechts von vorher festgelegten neuen oder aus dem Verzeichnisbaum entnommenen Einheiten haben sollen, kann festgelegt werden. Man sucht im ganzen Korpus bzw. in beiden Korpora mit spezifischen Fragestellungen: z. B. wie die Einheit Text konzeptuell näher spezifiziert wird. Bspw. können semantisch spezifizierend wirkende Attribuierung über die linksseitigen Mitspieler als Adjektivattribute gesucht werden. Auf das Quellkorpus bezogen zeigen sich Schwerpunkte der Texte zu den den Textanalyse-Videos vom TAP, nämlich wie spezifische Mittel verwendet werden um Textverdichtung und Textoptimierung zu erreichen.
Nutzungsszenario 2: Die Arbeit mit einem Spezialkorpus
Material: ein Spezialkorpus, ein Referenzkorpus
Fragestellung: Sie nutzen ein Korpus, möchten aber nicht mit „absoluten“ Werten arbeiten, sondern wissen, ob die gewonnenen Ergebnisse nur in ihrem Spezialkorpus in dieser Weise, Form und Frequenz/Häufigkeit vorkommen? Dies ist möglich, indem man sich ein die deutsche Sprache möglichst repräsentativ abbildendes sogenanntes Referenzkorpus zusammenstellt. Durch den statistischen Abgleich des eigenen Spezialkorpus mit diesem Referenzkorpus erhält man nicht nur relative Werte, sondern statistisch valide Wahrscheinlichkeitsverteilungen, die abbilden wie sich bspw. das Vorkommen eines Wortes oder einer Wortform im Spezialkorpus zum Vorkommen im Referenzkorpus verhält. Weitere Informationen zur absoluten, relativen Häufigkeit und Wahrscheinlichkeitsverteilung finden Sie unter Links. Für eine Zusammenstellung eines Referenzkorpus sind unterschiedliche Datenquellen geeigenet z. B. das DeReKo des Instituts für deutsche Sprache Mannheim, das DWDS oder kommerzielle Datenbanken wie LexisNexis. Mehr zum Thema Korpora finden Sie auf unseren Seiten unter Korpora.
Die Beschreibung der Analyse folgt der Vergleichs zweier Korpora mit besonderem Blick auf das Spezialkorpus und wie sich die Ergebnisse zum allgemeinen Sprachgebrauch verhalten.
Weiterführende Links:
Webseite von Friedemann Vogel
https://www.friedemann-vogel.de/index.php/software
Youtube-Kanal von Friedemann Vogel
Quelle: https://www.youtube.com/watch?v=TRSNFiTX8ZI
Häufigkeitsmaße in der Korpuslinguistik
http://www1.ids-mannheim.de/kl/dokumente/freqMeasures.html
http://homepage.ruhr-uni-bochum.de/Stephen.Berman/Korpuslinguistik/H%C3%A4ufigkeitsma%C3%9Fe.html