
Was ist CATMA?
Catma 7 ist ein webbasiertes Tool zur Annotation schriftlicher Daten. Annotationen sind (z.B. linguistisch motivierte) Anreicherungen von Texten mit zusätzlichen Informationen, die über eine ausdrucksseitige Suchanfrage nur schwer werden können, etwa zur Metaphorik, Attribuierung oder zu Strategien der Themenentfaltung. Texte lassen sich in Catma auf verschiedenen Ebenen und auch kollaborativ mit mehreren Annotatoren gleichzeitig codieren. Das Taggen von Textteilen bietet nicht nur Unterstützung beim close reading und der Deutung von Texten. Gezielte Suchanfragen erleichtern vor allem das Entdecken sprachlicher Mittel, die seriell in den vorher ausgezeichneten (=annotierten) Umgebungen auftreten. Das Tool vollzieht somit methodisch eine Pendelbewegung zwischen qualitativen und quantitativen Auswertungsschritten. Es unterstützt gängige Formate wie UTF-8, docx und pdf und erlaubt Suchanfragen mit regulären Ausdrücken.
Vorteile:
- einfache, intuitive Bedienung
- übersichtlicher Workflow von der Korpuserstellung bis zur Analyse
- leichter Datenexport z.B. in Excel
- komplexe Suchanfragen möglich
- integrierter POS-Tagger
- erleichtert die kollaborative Annotation im Team
- webbasiert, kein Download, unabhängig vom Betriebssystem
Nachteile:
- generell hoher Zeitaufwand für das manuelle Annotieren
- keine Ansicht des Originaldokuments
- nur für kleine Korpora
Nutzungsszenario:
Häufig sind es beiläufige Beobachtungen im Alltag, die zu einer linguistisch interessanten Fragestellung führen. Das können auffällige Formulierungen sein, Mode- und Tabuwörter, aber auch sprachliche Zweifelsfälle. Am Beispiel der relativ neuen Nahrungsmittelkategorie Superfood aus dem aktuellen Ernährungsdiskurs werden im Folgenden die Möglichkeiten der korpuslinguistischen Analyse mithilfe des Annotationsprogramms Catma aufgezeigt.
Ausgangspunkt ist die Beobachtung, dass der aus der Lebensmittelwerbung stammende Anglizismus Superfood in den öffentlichen Medien kontrovers diskutiert wird. Man kann sich nun fragen, mit welchen sprachlichen Mitteln die semantischen Kämpfe über Sinn und Nutzen der Superfoods ausgetragen werden. Treten in befürwortenden und ablehnenden Positionen zur Einordnung von Nahrung als Superfood wiederkehrende Bezeichnungen oder typische Formulierungen auf? Das Spektrum von sachlich-informierenden bis ablehnenden Sprachhandlungsmustern wirkt zunächst sehr breit:
Das leisten die Superfoods (Focus online, 26.10.2018)
Man kann sich Superfoods aufs Brot oder ins Gesicht schmieren, es gibt sogar Hundefutter mit Superfood. (Zeit Magazin, 14.2.2018)
Superfood – Kann diese Superfrucht lügen? (Zeit Magazin, 14.2.2018)
Vergesst hippes Superfood! (Focus online, 7.6.2018)
Wenn man nun danach fragt, wie typischerweise Äußerungen gestaltet sind, die Superfood näher definieren oder die die Kategorie kritisch aufgreifen und ablehnen, wäre es praktisch, Listen zu haben, die einmal alle Äußerungen pro und einmal alle Äußerungen contra Superfoods aufführen. Darüber hinaus ließen sich zwei Übersichten mit Bezeichnungsvarianten erstellen, in denen die als Superfood klassifizierten Nahrungsmittel z.B. durch Adjektive näher beschrieben werden. Diese Liste händisch anzufertigen, wäre ein enormer Aufwand und das Ergebnis wenig nachhaltig. Annotierte Belege lassen sich in Catma hingegen nach verschiedenen Gesichtspunkten sortieren; zudem sind die Annotationen für diverse Suchabfragen nutzbar. Nachdem man zunächst ein neues Projekt erstellt hat („Create new project“) bildet Menü A den weiteren Workflow ab (Screenshot 1).

Texte für ein Korpus speichern
Zunächst ist im Project-Bereich unter Resources „Documents & Annotations“ (B) ein Korpus zusammenzustellen. Für die exemplarische Annotation wurden neun Texten ausgewählt, die zum Thema Superfoods in Online-Artikeln der Zeitschriften Focus, Spiegel und Zeit erschienen sind. Sie wurden über „Add Documents“ hinzugefügt (Screenshot 2) und können optional mit Metadaten versehen werden. Die Texte können direkt über die URL in Catma hinzugefügt werden, was jedoch eine recht fehlerträchtige Übertragungsart ist, bei der überflüssige Navigationsleisten oder Werbezeilen mitkopiert werden. Daher empfiehlt sich das Speichern in Word oder im Texteditor (z.B. im UTF-8-Format). Catma erzeugt automatisch zu jedem hinzugefügten Text eine eigene Annotationsdatei („Annotation Collection“), in der später die Annotationen gespeichert werden. Man kann aber auch weitere Annotationsdateien zu jedem Text manuell erstellen.

Ein Tagset erstellen
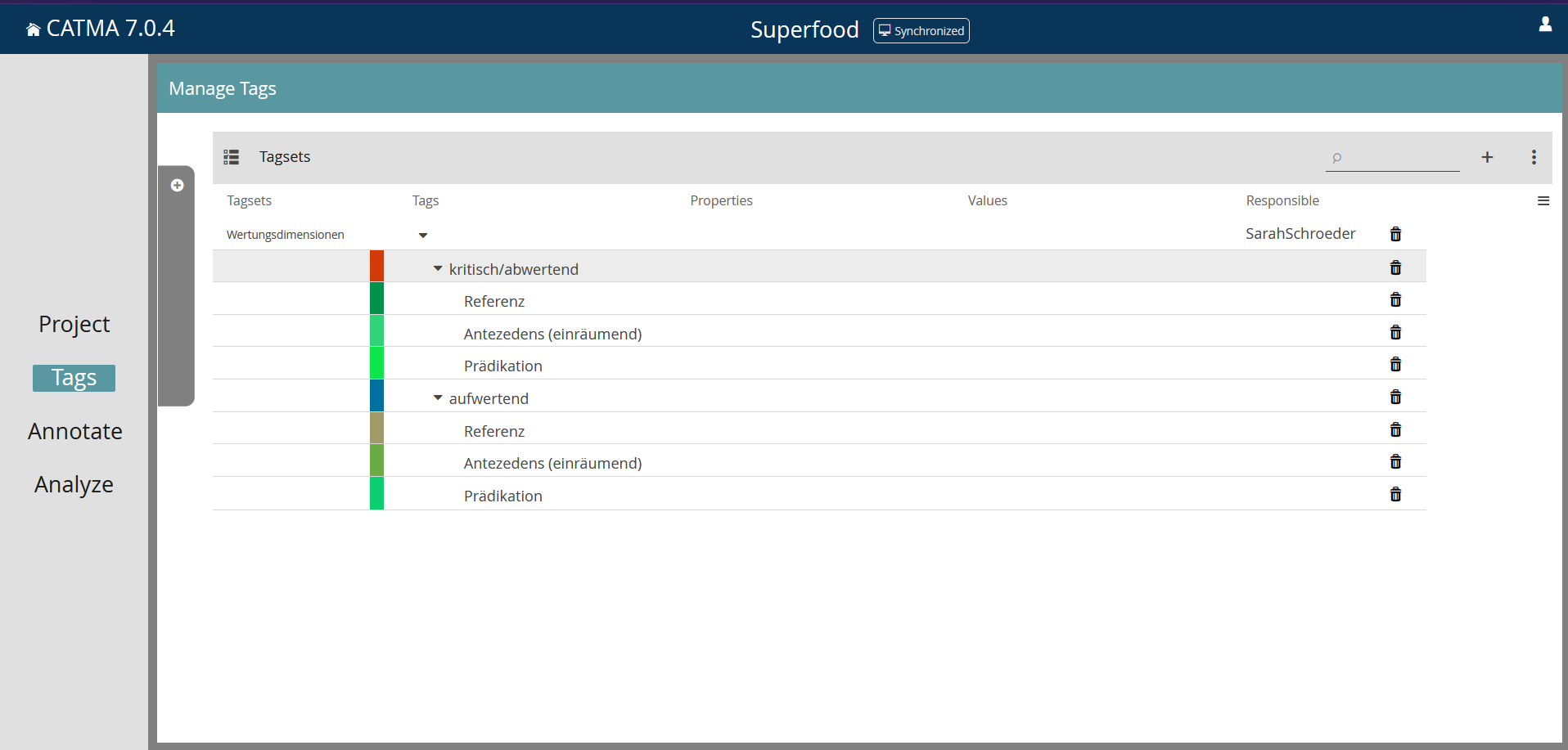
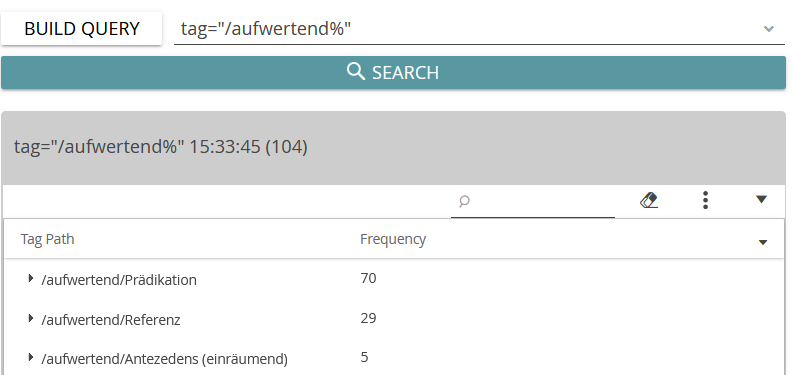
Bevor es ans Annotieren geht, muss ein Tagset, d.h. ein Kodierschema erstellt werden (C oder unter „Tags“ im Menü A), das der Kennzeichnung der Texte zugrunde liegt. Das für die Beispielanalyse erstellte Tagset „Wertungsdimensionen“ enthält die beiden Tags kritisch/abwertend und aufwertend mit jeweils drei Subtags (Screenshot 3). Die Architektur des Tagsets kann in Catma jederzeit auch während der Annotation verändert werden. Dies war erforderlich, weil sich herausstellte, dass neben den referierenden Bezeichnungsvarianten für Superfood (Referenz) und den prädizierenden Aussagen (Prädikation) auch Einräumungen vorkommen, auf die dann die eigentliche Kritik oder die Positivbewertung erst folgt nach dem Muster „Jeder weiß: Superfoods sind teuer – trotzdem machen sie fit“ oder „Ganz klar: Die Wirkung von Superfoods ist unbestreitbar – trotzdem gibt es heimische Alternativen.
Annotieren
Nun kann das eigentliche Annotieren beginnen. Dafür ist es nötig, ein Dokument zu öffnen, indem entweder direkt ein Text doppelt angeklickt wird (B) oder man im Menü (A) „Annotate“ anklickt. Bei dieser Variante öffnet sich ein Menü, in dem man den gewünschten Text sowie das Tagset auswählen kann (Screenshot 4).
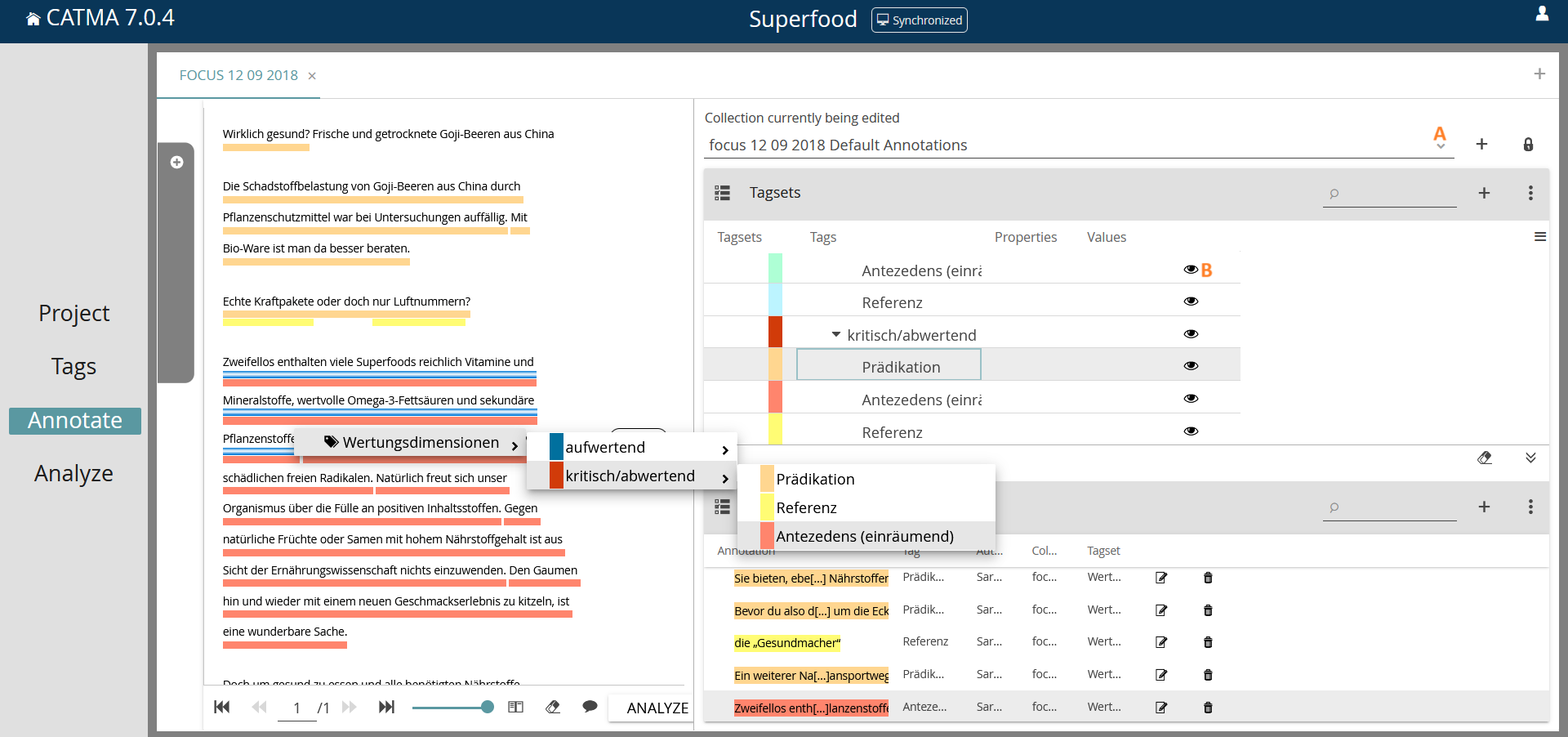
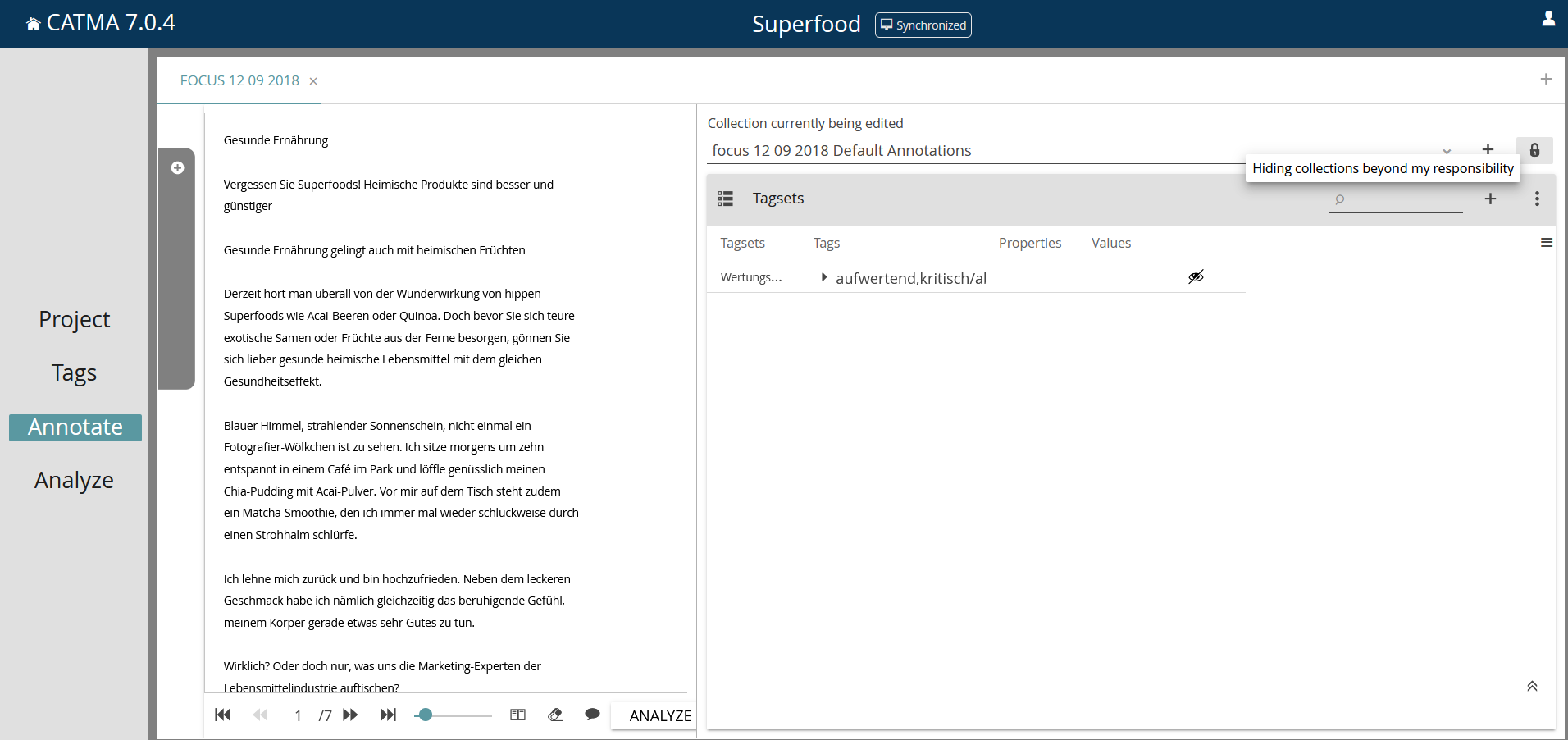
Wenn mehrere Annotation Collections zu einem Text existieren, muss zunächst ausgewählt werden, mit welcher Datei gearbeitet werden soll (Screenshot 5 – A). Bei jedem neuen Öffnen eines Textes ist auch wichtig, das Augen-Symbol (B) anzuklicken, damit bereits vorhandene Annotationen sichtbar werden. In Catma sind diese beim Öffnen eines Textes sonst zunächst verborgen. Ist das Tagset geöffnet (Screenshot 5), müssen zur Codierung der Zeichen, Wörter, Phrasen oder längerer Textpassagen die entsprechenden Abschnitte mit dem Cursor markiert werden. Sie lassen sich anschließend entweder durch einen Klick auf den entsprechenden Tag einfärben oder per Rechtsklick auf den markierten Textabschnitt, worauf sich ein neues Menü öffnet.
Analysen mit dem Query Builder
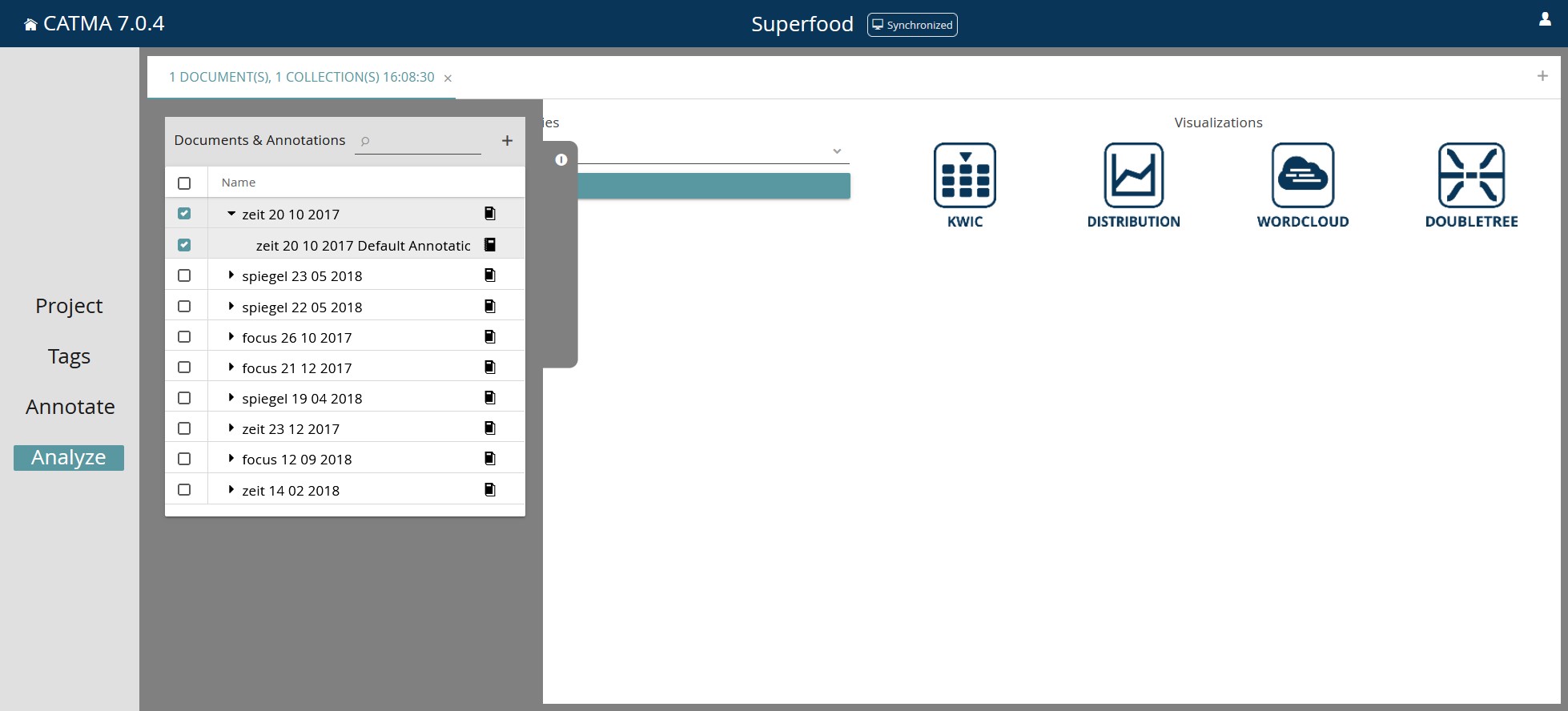
Auch wenn das Codieren per Mausklick etwas zügiger sein mag als die händische Annotation, wird es korpuslinguistisch in Catma erst interessant mit den nachgelagerten Analysefunktionen unter „Analyze“ (Screenshot 6). Gesucht werden kann sowohl nach konkretem Sprachmaterial (Wörter, Wortbestandteile und Phrasen) als auch nach abstrakten Tags. Man kann entweder nur in einem konkreten Text suchen oder per Klick in das Kästchen ganz oben neben „Name“ die Suche auf das gesamte Korpus beziehen. Wenn nur einzelne Texte ausgewählt werden, muss auch die Annotation Collection unterhalb des jeweiligen Textes in die Suche miteinbezogen werden (falls Tags zur Suche verwendet werden sollen). Bei der Formulierung einer Suchanfrage unterstützt der Query Builder, der alle Eingaben in eine Suchsyntax „übersetzt“. Für eine ausführliche Beschreibung einfacher und komplexer, d.h. verfeinerter und weiter gefilterter Suchanfrage ist das Manual zu empfehlen.
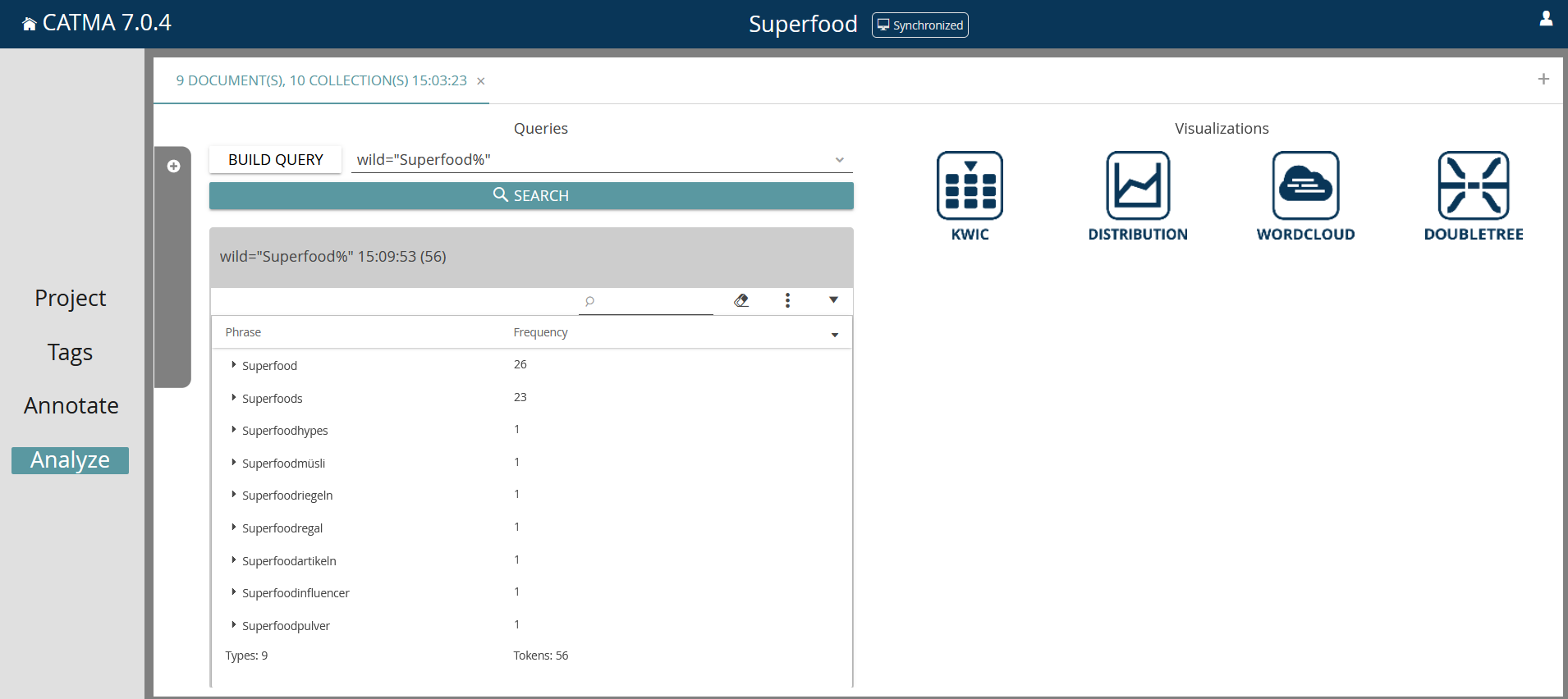
In der Wörterliste und auch bei der Suche nach Wortformen berücksichtigt Catma stets Groß- und Kleinschreibung (case sensitive). Bei der Suche lässt sich beliebiges Sprachmaterial mit den gängigen regulären Ausdrücken oder mit Platzhaltern, so genannten Wildcards, kombinieren wie z.B. bei der Suchanfrage [wild=“Superfood%“], bei der das Wort Superfood sowie alle Flexionsformen und Komposita aufgelistet werden (Screenshot 7).
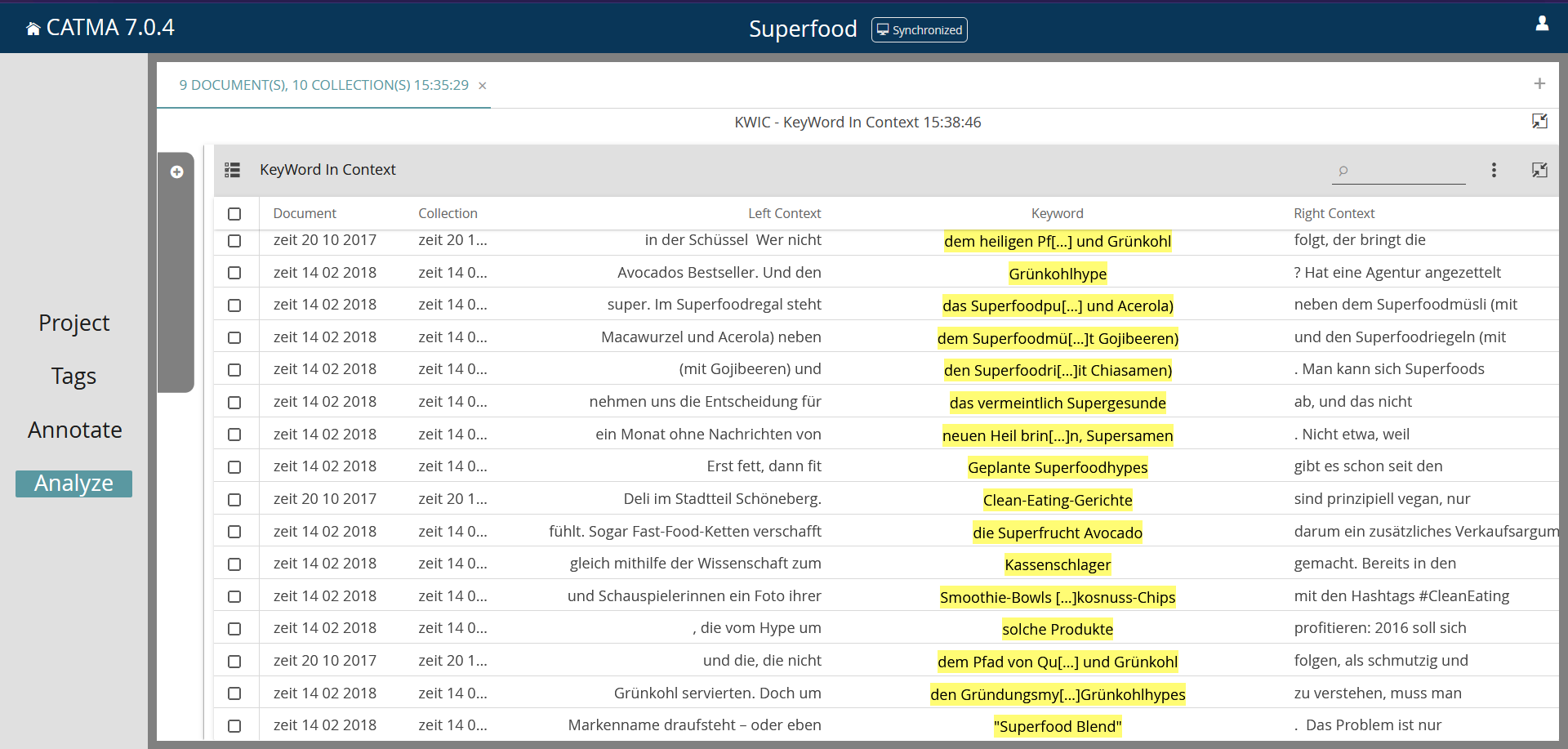
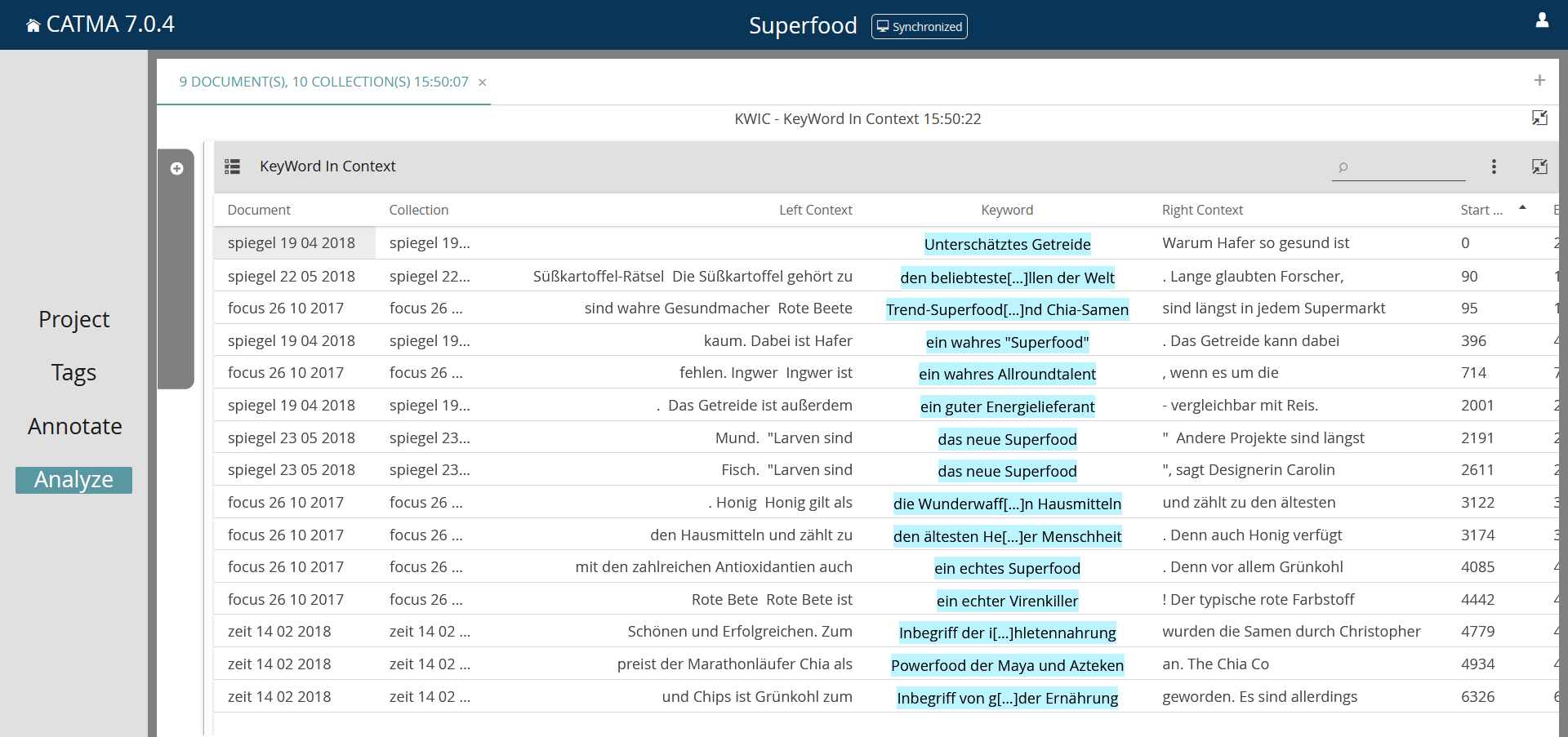
Über die Auswahl „KWIC“ unter „Visualizations“ kann man sich den Suchbegriff im Kontext anzeigen lassen, über das Pfeil-Symbol unter „Select“ werden ausgewählte Treffer in der KWIC-Übersicht angezeigt, z.B. nur die Form Superfood (Screenshot 8). Zusätzlich ist es möglich, über das Symbol der drei Punkte ein Menü zu öffnen, hier können z.B. alle Treffer ausgewählt werden oder die Ergebnisse exportiert werden. Catma sichert die Daten dann im CSV-Dateiformat („Comma-separated values“), dabei handelt es sich um eine spezielle Textdatei, bei der die einzelnen Angaben durch Kommas getrennt sind. Diese Dateien können z.B. mit Excel geöffnet und bearbeitet werden. Dazu in Excel unter „Daten“ die Option „aus Text/CSV“ wählen, um die Datei zu importieren. Werden Sonderzeichen nicht korrekt angezeigt, kann es alternativ auch hilfreich sein, die exportierte CSV-Datei zunächst mit einem Texteditor (z.B. Windows-Editor) zu öffnen und dann beim Speichern die Codierung „UTF-8 mit BOM“ zu wählen.
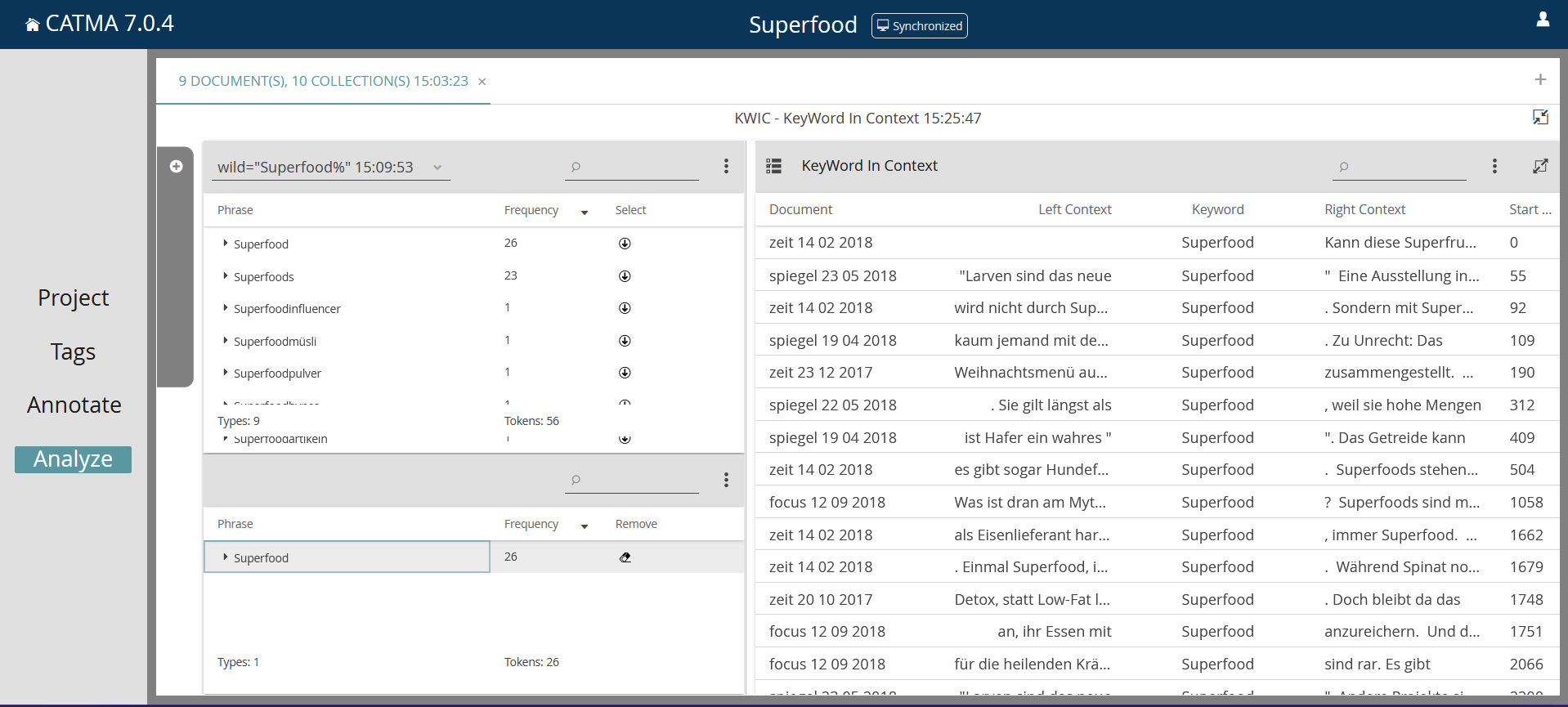
Dank der vorgelagerten Annotation können die Treffer für die Bezeichnung der Superfoods nun nach aufwertenden und abwertenden Bedeutungsaspekten sortiert werden. Im Query Builder muss dafür die Suche nach Tags eingestellt werden (Screenshot 9). In der Übersicht ist erkennbar, dass sowohl auf Bezeichnungsebene als auch in den Prädikationen die kritischen Bewertungen in den ausgewählten Texten überwiegen (Screenshot 10 und 11). In den KWIC-Übersichten der auf- und abwertenden referenzierenden Ausdrücke (Screenshot 12 und 13) treten verschiedene, möglicherweise typische Ausdrucksweisen auf: die religiöse Metaphorik bei den abwertenden Bezeichnungsvarianten (z.B. neuen Heil bringenden Superfrüchten, dem heiligen Pfad von Quinoa und Grünkohl) und die Zuschreibung von Gesundheitsfunktionen in den aufwertenden Bezeichnungen (z.B. den ältesten Heilmitteln der Menschheit, wahre Gesundmacher).
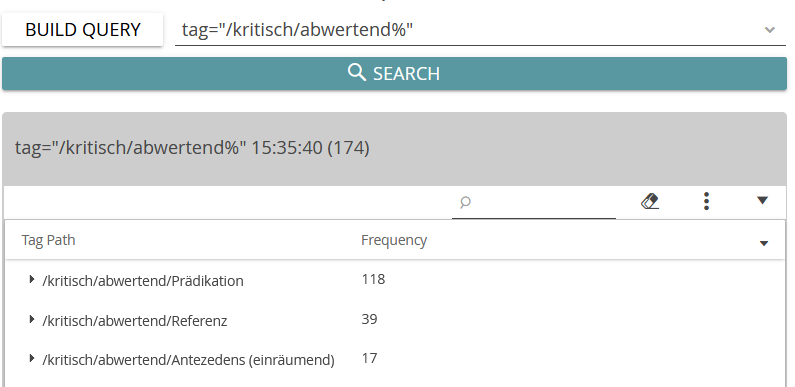
Aus den abwertenden Prädikationen heraus gewinnt man einen Eindruck davon, wogegen sich die Kritik an der Lebensmittelkategorie Superfoods richtet, und zwar gegen die Zuschreibung moralischer Werte an Nahrungsmittel (Einteilung von Nahrungsmitteln in Gut und Böse so gefährlich), gegen religiöse Ritualisierungen (Parallelen zu religiösem Extremismus) und auch gegen Verkaufsstrategien im Gewand von Gesundheitshandeln (teuren und angepriesenen Migranten). Auf der befürwortenden Seite stehen Medizinalisierungen: Superfoods haben antibakterielle Wirkung, sie entfalten ein entzündungshemmendes Potential und enthalten ähnlich wie Arzneien heilende oder präventiv wirksame Inhaltsstoffe (reich an X). Diese Zusammenstellung zeigt, dass Auswertungen auf der Basis quantitativer Ergebnisse Interpretationen einerseits ermöglichen und andererseits auch erfordern.
Visualisierung
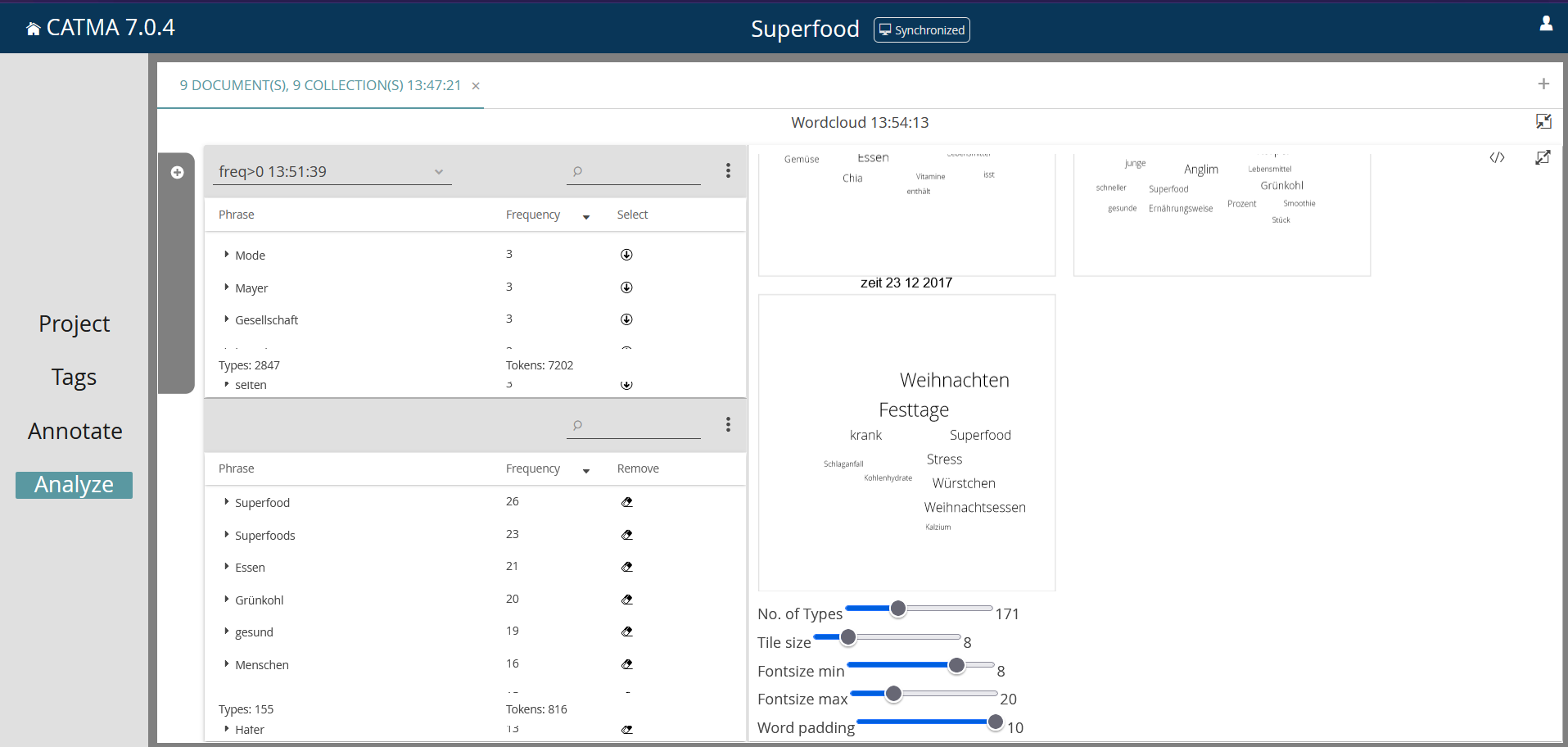
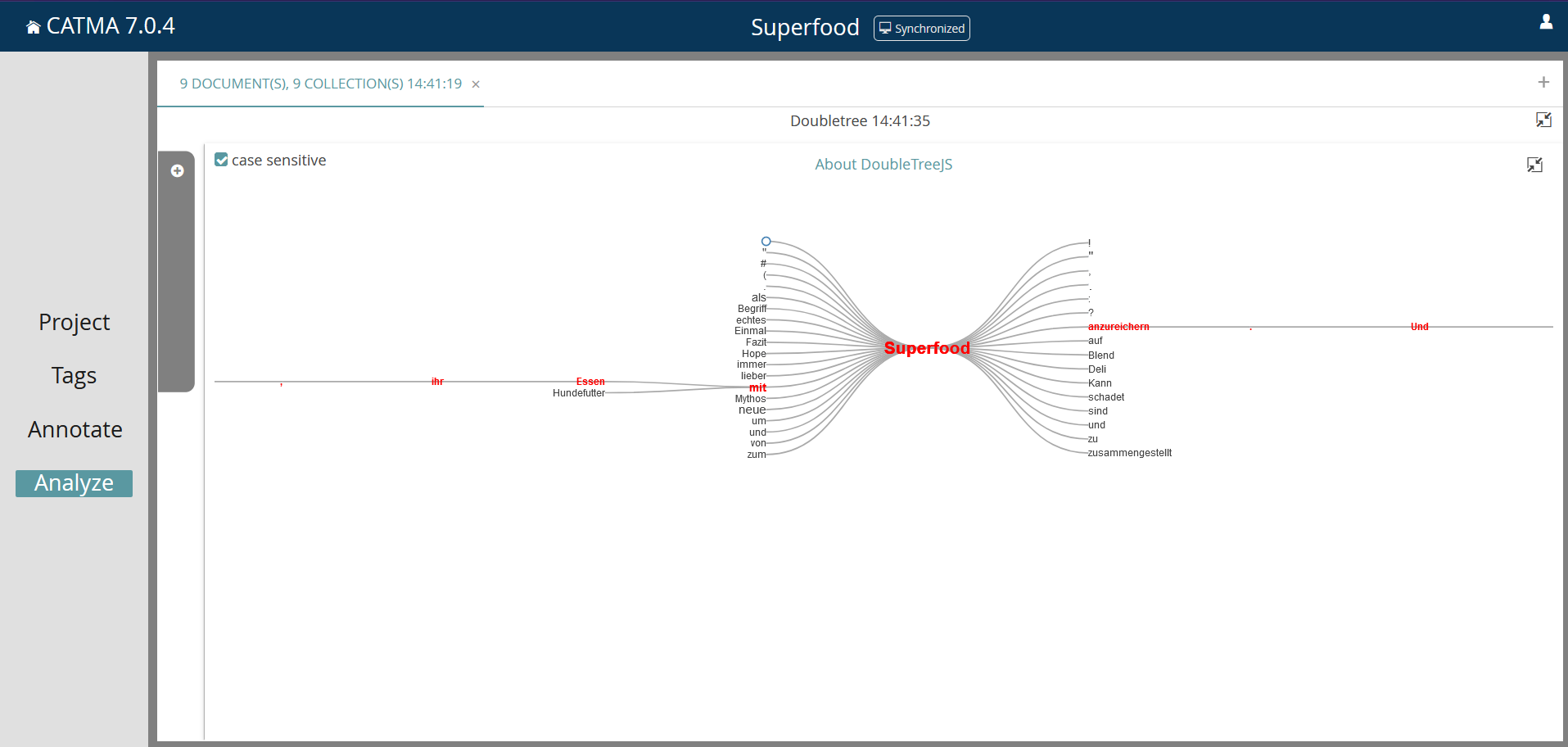
Schließlich stehen im Anschluss an die Analyse drei Visualisierungsmöglichkeiten zur Verfügung. Zunächst kann man sich häufige Wörter als „Wordcloud“ (Screenshot 14) anzeigen lassen. Wortverbindungen können ausgehend von einer gewählten Wortform als „Double Tree“ angezeigt werden (Screenshot 15). Um die Verteilung und den Verlauf einer oder mehrerer Wortformen für jeden einzelnen Text aus dem Korpus zu erfassen, kann darüber hinaus eine „Distribution“ erstellt werden.
Die einfachste Möglichkeit ist die Erstellung einer Wordcloud, dazu kann einfach der kleine Pfeil im Feld „Select or enter a free query“ angeklickt werden und dann „Wordlist (feq>0)“ ausgewählt werden. Catma listet so alle Wörter und die Häufigkeit der Verwendung auf, wählt man nun die Wordcloud als Visualisierung können entweder alle Treffer oder nur ausgewählte in die Anzeige einbezogen werden. Im Beispiel (Screenshot 14) wurden nur Inhaltswörter gewählt. Es wird zu jedem Text des Korpus eine eigene Wordcloud erstellt, unterhalb der Grafiken können noch einige Einstellungen (Schriftgröße etc.) vorgenommen werden.
Wer die Ergebnisse, das Tagset, Dokumente oder das gesamte Korpus anderen zur Verfügung stellen möchte, hat die Möglichkeit, das Projekt mit einem Team zu teilen. Hier gibt es zwei Möglichkeiten, Personen einzuladen. Entweder, man klickt auf der Projektseite im Bereich „Team“ auf das Plussymbol und trägt in der folgenden Eingabemaske die E-Mail-Adresse (die zur Catma-Anmeldung verwendet wurde) ein, oder man klickt hier zunächst auf die drei Punkte und wählt dann „Invite Others to the Project“. Bei dieser Variante können mehrere neue Teammitglieder gleichzeitig beitreten. Der einladenden Person wird von Catma ein Einladungscode angezeigt, dieser kann dann von den neuen Teammitgliedern im Catma-Startmenü mithilfe der Kachel „Join Project“ verwendet werden. Der Code ist ungültig, sobald die einladende Person „Stop Invitation“ anklickt.
Im Team können von mehreren Personen Annotationen zu denselben Texten erstellt werden, entweder mit demselben Tagset, um anschließend Abweichungen und Übereinstimmungen zu ermitteln (Annotator-Agreement), oder mit unterschiedlichen Tagsets, so dass kollaborativ auf mehreren Ebenen annotiert wird. Eine Mehrebenen-Annotation kann wiederum für komplexe Suchanfragen genutzt werden. Bezogen auf das vorliegende Beispiel ließe sich beispielsweise zusätzlich über eine Metaphernannotation erheben, welche metaphorischen Ausdrücke im Umfeld von Pro- und Contra-Argumentationen auftreten. Entweder, man erstellt/nutzt für jede Person eine eigene Annotation-Collection (um Annotationen nach Urheber zu unterscheiden), es ist aber auch möglich, gemeinsam an einer Annotation Collection zu arbeiten, was jedoch zu Problemen führen kann. Das kleine Schlosssymbol neben der Annotation Collection (in der Annotationsansicht eines Textes) entsperrt die Collection und ermöglicht die Bearbeitung.
Durch einen Klick auf „Sync“ (ganz oben im Projekt-Bereich) werden Daten/Änderungen zwischen den Teammitgliedern synchronisiert.
Weiterführende Links:
https://catma.de/how-to/compact-manual/
http://catma.de/wp-content/uploads/2017/08/CATMA_Tutorial_2017_08_03.pdf
http://catma.de/wp-content/uploads/2017/05/catma4_manual.pdf