
Was ist EXMARaLDA?
EXMARaLDA ist ein Programm zur Transkription und Annotation von vorwiegend mündlichen Sprachkorpora, wird aber auch für die Be- und Verarbeitung schriftlicher und multimodaler Kommunikate (Videos) genutzt. Die Software beinhaltet einen Transkriptions- und Annotationseditor (Partitur-Editor), ein Tool zum Verwalten von Korpora (Corpus-Manager) und einem Such-, Filter- und Analysewerkzeug (EXAKT).
Vorteile:
- gängiges, weit verbreitetes Annotationstool, wird fortwährend optimiert
- Bearbeitung von Text, Audio und/oder Video
- Export in viele Formate möglich (PRAAT, ELAN, FOLKER, TEI etc.)
- unterstützt viele Sprachen
- gute Supportangebote (FAQs, How to’s, Video-Tutorials, Workshops etc.)
- generiert korpusübergreifende Statistiken
- diverse Korpus-Wartungsfunktionen
- umfangreiche Suchanfragen möglich (je nach Annotation!)
- Suchfunktionen intuitiv anwendbar (inkl. Hilfen)
- Suchergebnisse können multimodal angezeigt werden (Text, Audio, Video)
Nachteile:
- Einarbeitungszeit
- volle Funktionalität nur mit allen drei EXMARaLDA-Tools
- arbeitet langsam bei großen Datenmengen
- Originaltext im Editor kaum bearbeitbar/änderbar
- Filter- und Sortierfunktionen sind begrenzt (EXAKT)
- Ansicht der Suchergebnisse wenig benutzerfreundlich (EXAKT)
„Getting started“ – Schritt-für-Schritt-Anleitung
Arbeitsschritt 1: Annotieren mit dem „Partitur-Editor“
Laden Sie sich EXMARaLDA für Ihr jeweiliges Betriebssystem unter http://exmaralda.org/de/offizielle-version/ runter (unterstützt Windows, MacOS und Linux; Stand: 03/2017)
Speichern Sie die Textdatei „Buechersammlung“ auf Ihrem Betriebssystem.
Öffnen Sie den EXMARaLDA Partitur-Editor und klicken Sie auf den Reiter Datei und auf Importieren…
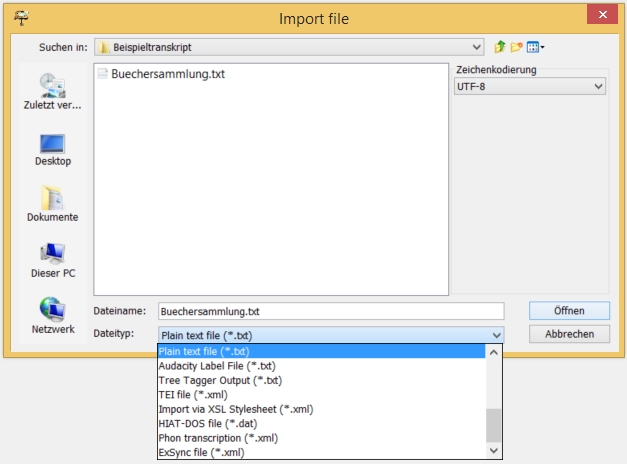
Wählen Sie im Auswahlfenster die heruntergeladene .txt-Datei aus. Wählen Sie als Zeichenkodierung UTF-8 aus und als Dateityp „Plain text file (*.txt), anschließend klicken Sie auf Öffnen
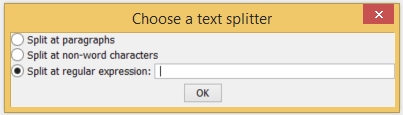
Der Partitur-Editor fragt Sie nun, wie das Transkript segmentiert, also in kleinere Einheiten zerlegt werden soll. Wählen Sie hier den Auswahlpunkt „Split at regular expression“ und drücken Sie die Leertaste (damit weisen Sie den Editor an, nach jeder Leertaste im Originaldokument eine Segmentierung einzufügen. Sie erhalten dann eine durchlaufende Transkriptionsspur im Partitur Editor.
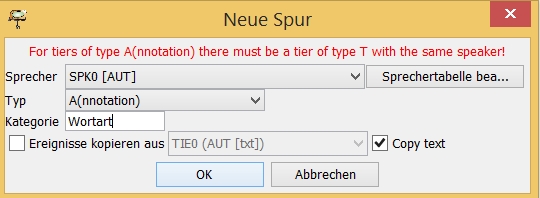
Um das Transkript nun manuell zu annotieren, wählen Sie den Reiter Spur und Spur anfügen. Im erscheinenden Dialogfenster legen Sie fest, nach welchen Kriterien Ihre neue Spur definiert sein soll. Zum Anreichern des Textes mit grammatischen Informationen wählen Sie unter „Typ“ A(nnotation) aus und geben Sie bei „Kategorie“ den jeweiligen Begriff der Untersuchungskategorie ein, etwa „Wortart“, „Satzglied“, „Flexion“ o.Ä. Die Untersuchungskategorie definieren Sie selbst. (Wichtig: Unter „Sprecher“ muss „SPK0“ eingestellt bleiben, damit der Editor eine Verknüpfung des Originaltextes mit Ihrer neuen Spur herstellen kann!)
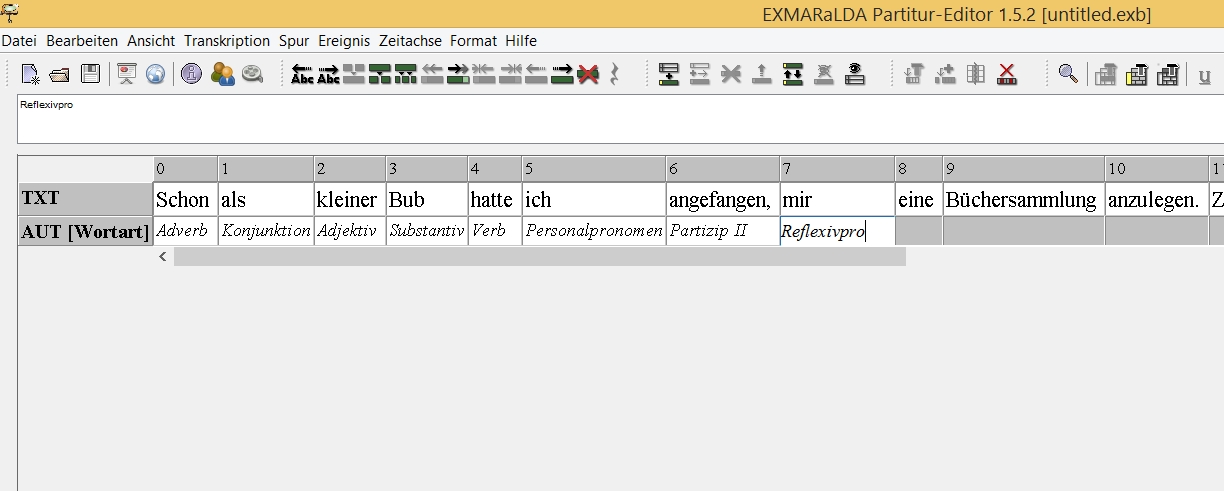
Nun können Sie mit der Annotation des Textes beginnen, indem Sie den einzelnen sprachlichen Einheiten die jeweilige Information zuweisen (Beispiel Abb.: Wortarten)
Nach dem gleichen Prinzip können Sie Ihre Annotation jetzt durch vielfältige weitere Spuren je nach Forschungsfrage anreichern: Spur –> Spur anfügen…–>Typ A(nnotation) –> Kategorie Satzglied/Flexion/Phrase/Satzart…
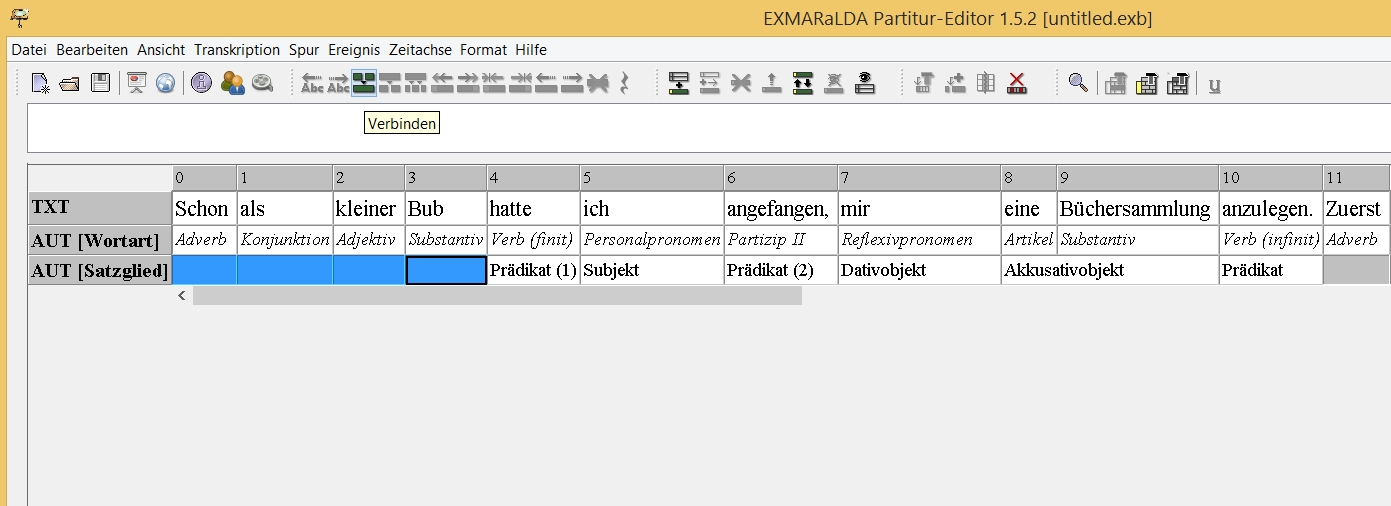
Wenn Sie einzelne Zellen verbinden möchten, etwa bei der Satzgliedbestimmung, markieren Sie die entsprechenden Felder und klicken auf das „Verbinden“-Symbol in der Werkzeugleiste oder alternativ über Ereignis–>Verbinden.
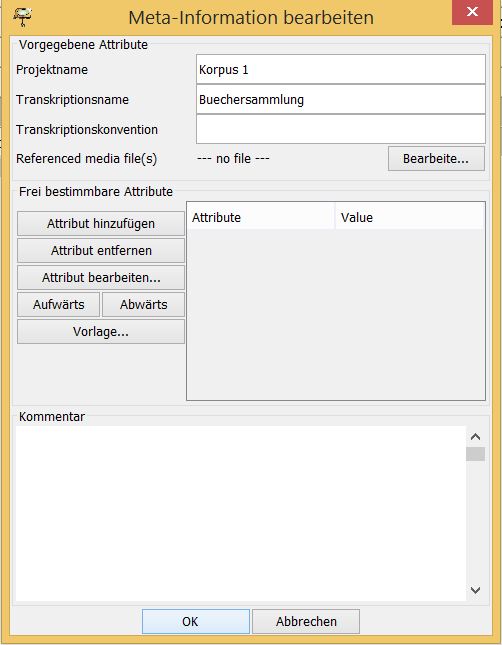
Ein letzter wichtiger Schritt ist das Eintragen der Meta-Informationen der Transkription. Wählen Sie hierzu unter dem Reiter Transkription —> Meta-Information und tragen Sie in die Felder Korpusname und Transkriptionsname einen jeweiligen Namen ein (wollen Sie mehrere Transkriptionen einem Korpus zuordnen, so tragen Sie entsprechend bei „Korpusname“ immer den gleichen Namen ein). Die restlichen Einstellungen sind für einen ersten Zugang zunächst einmal unwichtiger:
Speichern Sie abschließend das Dokument ab. Eine vollständige Beispielannotation zum Ausgangstext „Buechersammlung“ finden Sie hier. Speichern Sie sie auf Ihrem Betriebssystem.
Arbeitsschritt 2: Korpuserstellung mit dem „COMA“-Korpusmanager
Bevor Sie mit „COMA“ ein Korpus anlegen, ist folgender Schritt wichtig: Die anzulegende .coma-Datei muss auf einer höheren Ordner-Hierarchieebene abgespeichert werden als Ihre Transkriptionen. In unserem Beispiel liegt der Ordner „Buechersammlung“, in dem die Transkription gespeichert ist, innerhalb des Ordners „Buechersammlung Korpus“. Legen Sie also – auch für Ihre eigenen Transkriptionen – eine Ordnerstruktur der folgenden Art an:

Öffnen Sie anschließend den EXMARaLDA „COMA“-Korpusmanager.
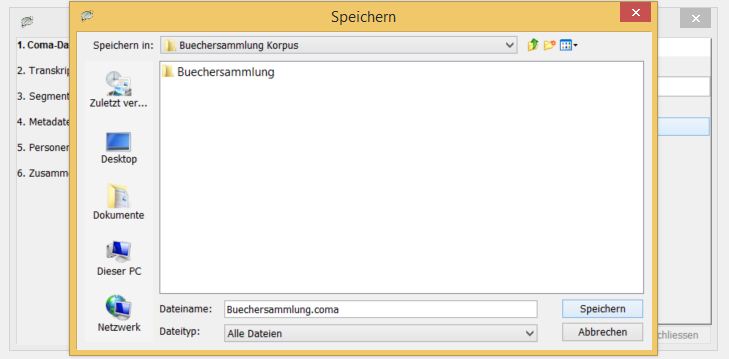
Klicken Sie auf den Reiter Datei –> Korpus aus Transkriptionen erstellen. Vergeben Sie einen Korpusnamen und klicken Sie bei Coma-Datei auf auswählen… Die zu erstellende Korpusdatei muss nun auf der übergeordneten Ebene der Transkriptionen gespeichert werden, vgl.:
Die Software erkennt nun automatisch die Anzahl der im Zielordner gespeicherten Transkriptionen (in unserem Beispiel also genau eine .exb-Datei, die wir im „Partitur-Editor“ erstellt haben). Bei mehreren Transkriptionsdateien setzen Sie die Häkchen bitte jeweils an allen aufgelisteten Dateien mit der Endung „.exb“.
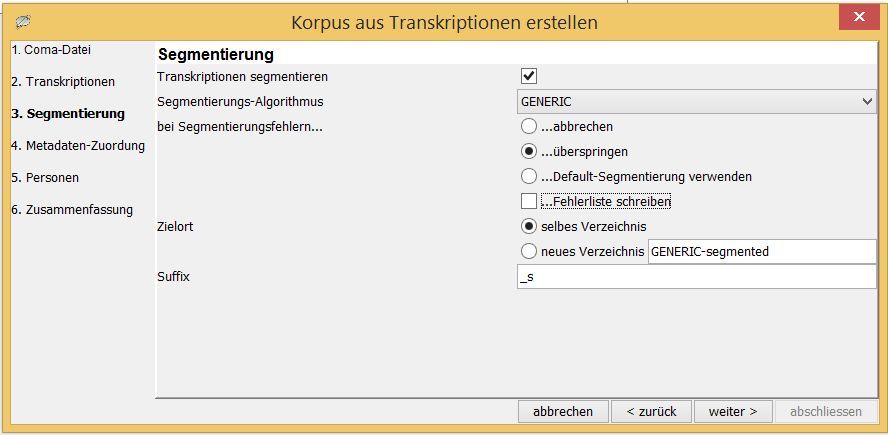
Nachdem Sie auf weiter> geklickt haben, erscheint ein Fenster, in dem Sie angeben, wie COMA die Transkription(en) verarbeiten soll. Setzen Sie ein Häkchen bei Transkriptionen segmentieren (die Software teilt so Ihren Text für die späteren Suchanfragen je nach Annotation in kleinere Einheiten). Für eine „klassische“ Segmentierung schriftsprachlicher Texte wählen Sie den Algorithmus GENERIC, die restlichen Einstellungen können Sie übernehmen.
Die Einstellungen der nachfolgenden Eingabefenster können Sie mit weiter> jeweils bestätigen. COMA legt abschließend ein Korpus an, in dem Sie links eine Auflistung der enthaltenen Transkriptionen sehen (in unserem Fall lediglich die Transkription „Buechersammlung“):
Für die Weiterarbeit mit Ihren Korpusdaten müssen Sie in COMA erst einmal nichts weiter tun. In Ihren Verzeichnissen sind nun die nötigen Dateien des Partitur-Editors und des Korpusmanagers gespeichert. Sollten Sie etwas vergessen haben oder einen Fehler gemacht haben, können Sie jederzeit eine neue .coma-Datei aus Ihren Transkriptionen erstellen.
Arbeitsschritt 3: Arbeiten mit dem Analyse- und Konkordanztool „EXAKT“
Wenn Sie den Schritten dieser Anleitung gefolgt sind, so müssten Sie in Ihrem Zielverzeichnis nun eine (oder mehrere) .coma-Dateien erstellt haben, die Grundlage für die Nutzung des eigentlichen Such- und Analysetools von EXMARaLDA, der Erweiterung EXAKT, ist bzw. sind.
Öffnen Sie das Programm und wählen Sie Datei —> Korpus öffnen… Suchen Sie nun die gespeicherte .coma-Datei, in der Sie Ihre Transkriptionen zusammengefasst und gespeichert haben, und öffnen Sie sie.
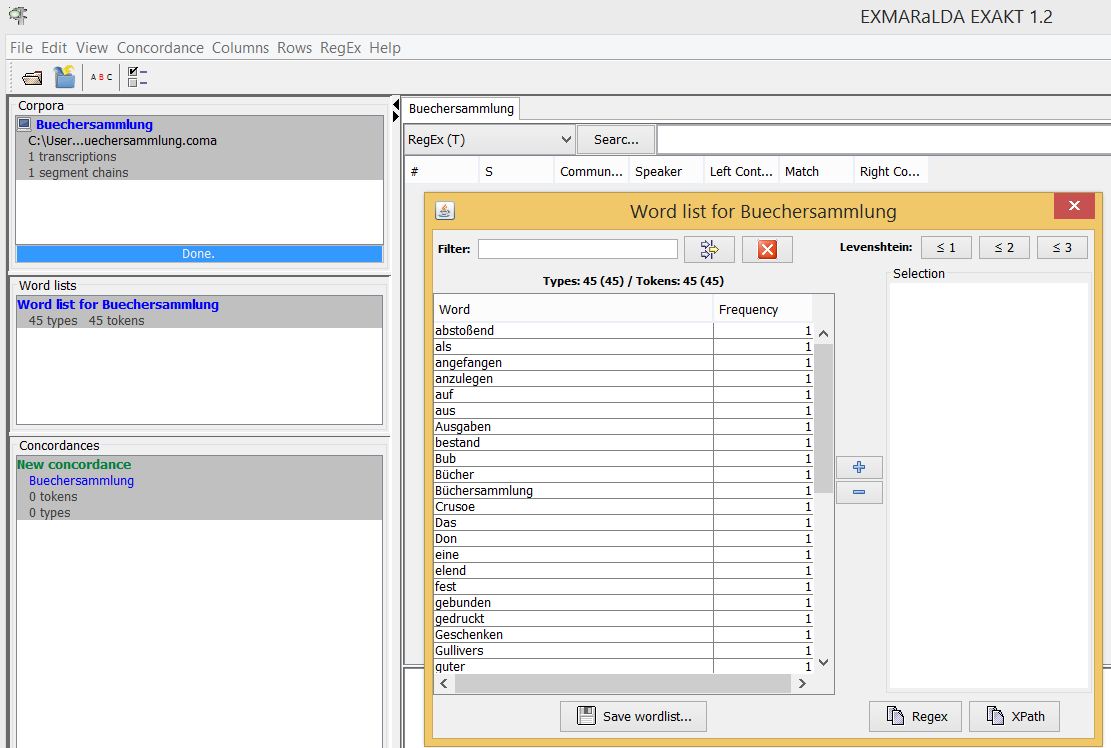
EXAKT bietet Ihnen nun an, eine automatische Wortfrequenzliste zu generieren, womit Sie bereits eine erste statistische Auswertung Ihrer Datensammlung erhalten. Die Wortliste können Sie im mittigen Feld auf der linken Seite öffnen. Unter Korpora (oben links) werden alle Korpora angezeigt, die in die Such- und Filterfunktionen von EXAKT integriert werden, vgl.:
Auf der rechten Seite der Benutzeroberfläche können Sie nun Ihre Transkription mitsamt der eigenen Annotationen durchsuchen und filtern. Hierzu klicken Sie auf das Bedienfeld RegEx(T). Hier legen Sie fest, in welchen Spuren Sie nach Informationen suchen wollen. In unserem Fall suchen Sie bei „RegEx(T)“ nach Einträgen im Originaltext und bei „RegEx(A)“ innerhalb der von Ihnen angelegten Annotationsspuren. Wenn Sie RegEx(A) auswählen können Sie aus der Liste der selbst angelegten Spuren eine Untersuchungskategorie auswählen und im Eingabefeld eine spezifische Annotation eintragen, nach der Sie Ihr Korpusmaterial filtern wollen. In der folgenden Abbildung wird eine Suchanfrage zur Annotationsspur „Wortart“ und der Kategorie „Adjektiv“ gestellt. EXAKT ermittelt sämtliche Einträge innerhalb des Korpus und listet die Ergebnisse untereinander auf:
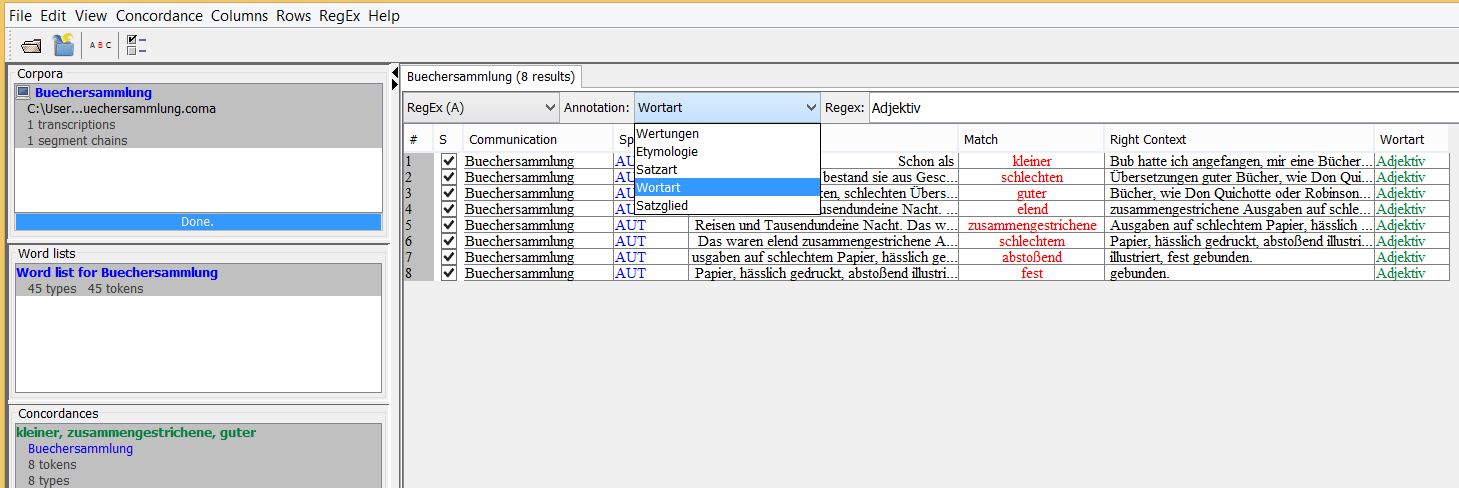
Unter Match wird Ihnen stets das Ergebnis angezeigt, das Sie mit dem Suchbegriff annotiert haben. Unter Linker Kontext und Rechter Kontext wird Ihnen das Ergebnis im Kontext des Gesamttextes angezeigt (das sog. „KWIC“: KeyWord In Context). Unter Communication wird Ihnen angezeigt, aus welcher spezifischen Transkriptionsdatei das Ergebnis gefiltert wurde.
Sie können nun diese sogenannte Konkordanzansicht nutzen, um Ihr Material je nach Fragestellung(en) zu untersuchen. Sobald Sie ein Ergebnis anklicken, zeigt EXAKT Ihnen weitere Informationen an, die Sie bei der Arbeit unterstützen können, etwa den Ganzsatz, in dem das Suchergebnis zu finden ist oder eine Übersicht Ihrer gesamten Transkription aus dem „Partitur-Editor“, vgl.:

Mit diesem Kenntnisstand zur Erstellung einer Transkription, der Zusammenstellung eines Korpus und der Recherche innerhalb des Untersuchungsmaterials können Sie EXMARaLDA bereits sehr effektiv nutzen. Die Software bietet zahlreiche weitere Funktionen, die Sie sich nach einer Phase der Einarbeitung selbst erschließen können. Nutzen Sie dazu auch die Online-Tutorials und/oder die weiterführenden Links unterhalb dieser Anleitung.
Weiterführende Links:
http://exmaralda.org/de/hilfesupport/
http://prowiki.ids-mannheim.de/bin/view/GAIS/TranskriptionEditoren#EXMARaLDA