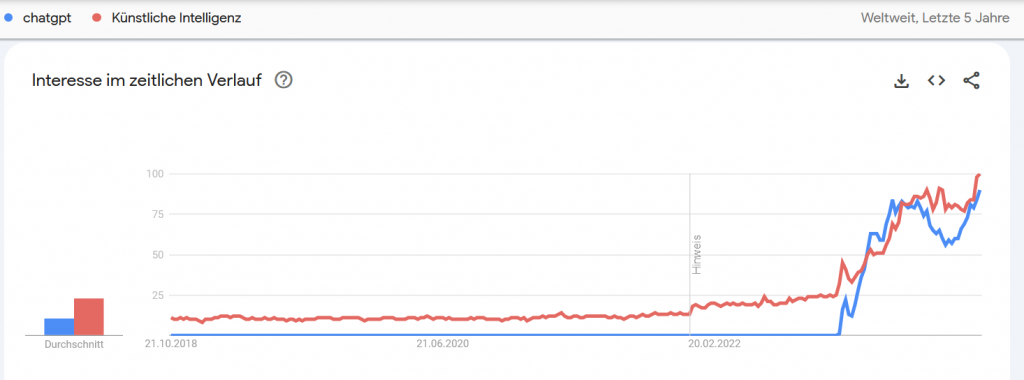
Künstliche Intelligenz (KI) ist in aller Munde. Wenige Themen dominieren allem Anschein nach öffentliche und auch politische Debatten in den neuen 20er-Jahren wie der Einfluss „intelligenter“ Systeme auf unser Zusammenleben. Dieser öffentliche Diskurs kennt auch keine Grenzen. So nimmt jede erdenkliche Person—mehr oder minder freiwillig—an Gesprächen rund um KI teil, sei es am Stammtisch, im Wartezimmer der Arztpraxis oder in der Hochschule.
Der aktuellen Debattenkultur nach könnte man den Eindruck gewinnen, mancher KI würden magische Fähigkeiten zugesprochen werden. Dass es relativ autonome und zugleich auch undurchsichtige Systeme gibt, ist auch nicht abzustreiten. Jedoch sind diese nie vollständig frei in ihrem Handeln, im wortwörtlichen Sinne. Dies gilt insbesondere für algorithmische Entscheidungsverfahren (AEV), die hier im Fokus liegen sollen. Denn diese entscheiden mittlerweile nicht nur darüber, wer einen Kredit kriegt und wer nicht.
Was leider weniger mediale Aufmerksamkeit erhält als die Frage danach, ob KI „uns irgendwann ersetzt“, sind Folgen der Diskriminierung, die Menschen durch Algorithmen und automatisierte Verfahren bereits heute erleiden. Sie erstrecken sich von „harmlosen“ Fehlern bei der Gesichtserkennung über Aussortierungen von Bewerber*innen für Arbeitsstellen, bis hin zur möglichen Profilierung insbesondere von Minderheiten als potenzielle Straftäter*innen, mit Folgen der Freiheitsberaubung (siehe Barr 2015; Crawford 2016; Angwin et al. 2016; Angwin 2016; Buolamwini und Gebru 2018). Mit algorithmischen Verfahren denke ich hier also weniger an bewährte Screening-Tools in der Medizin o.ä., sondern eher an Risikobeurteilungsprogramme, beispielsweise in Jugendämtern oder der Justiz. Der Zusatz, dass nicht alle Verfahren und KI-Systeme gleich sind, erscheint mir hier wichtig.

Und dennoch hält die Nichtregierungsorganisation (NGO) AlgorithmWatch fest, dass diese Verfahren niemals neutral sind und Daten nach menschengemachten Deutungsmodellen interpretiert werden (2016). Das Problem der Blackbox ist real, jedoch basiert die Entscheidungsfindung immer auf Überlegungen, die vom jeweiligen Entwicklungsteam vorausgesetzt wurden. Demnach sind AEV keine rein technologischen Systeme, die frei und objektiv operieren, sondern ein Stück Kultur selbst, die in ihren Entscheidungen gewisse Werte und Praktiken widerspiegeln (vgl. Seaver 2018, 379). Soll heißen, dass auch Sexismus, Rassismus und weitere Diskriminierungsformen ihren Weg in das Modell finden, sofern diese vom Entwicklungsteam vertreten werden oder sie sich dessen nicht bewusst sind (vgl. Crawford 2016)—ein weiterer Punkt für die Diversität am Arbeitsplatz!
Der nächste kritische Aspekt liegt in der Datenerhebung, die bei algorithmischen Entscheidungen berücksichtigt wird. Vorerst werden Individuen auf messbare Daten reduziert, anhand welcher das System seine Entscheidung trifft. Mit jedem Klick, den wir tätigen und mit jeder Information, die wir über uns hergeben, vervollständigt sich ein temporäres Mosaik von uns. Dies ist allerdings nur eine Approximation dessen, was uns als komplexe Individuen ausmacht. Diese Daten können an einer gewissen Stelle, zu einem bestimmten Zeitpunkt erhoben werden und tragen daraufhin an anderer Stelle zur Entscheidungsfindung bei. Zusätzlich können Daten aufgrund von statistischer Vergleichbarkeit vermischt und Menschen auf einer Basis beurteilt werden, die nicht in Gänze ihrer Situation entspricht, aber statistisch valide ist (vgl. Matzner 2016, 204). Hinzu kommen disproportionale Faktoren bei der Datenerfassung. Personen, die abhängiger vom Staat und Sozialleistungen sind, hinterlassen auch mehr Daten. Besserverdienende Personen und Familien werden weniger erfasst und folglich weniger beobachtet.
Was hat das jetzt mit Philosophie zu tun? Machen wir an dieser Stelle einen kleinen Exkurs. Hierzu schauen wir uns einige Gedanken und Konzepte des südafrikanischen Philosophen John McDowell an, insbesondere aus seinem Werk Geist und Welt. Hier untersucht er (angelehnt an Kant) Rationalität und unter welchen Voraussetzungen wir Urteile über die Welt treffen und begründen können. Laut ihm müssen unsere Aussagen über die Welt ein minimales Maß an empirischer Gegebenheit aufweisen, um sich rechtfertigen zu lassen (vgl. 2012, 11f.). In anderen Worten muss unser Urteil den Dingen so entsprechen, „wie die Dinge [eben] sind“ (ebd., 12). McDowell spricht auch vom „Tribunal der Erfahrung“ (ebd.): Unser Urteil stehe einer Art Gericht gegenüber, gebildet aus unserer leiblichen Erfahrung von der Welt, welche als externer Faktor eine rationale Kontrolle darüber ausübt, was wir wahrheitsgemäß über sie aussagen können. Wenn ich also sage, über mir fliegt ein Flugzeug, sollte dieses bestenfalls auch vorbeifliegen, zumindest meiner Wahrnehmung nach. Ohne diesen Realitätsbezug wäre mein Urteil „reibungslos“ (ebd., 91). Meiner Aussage fehle es damit an Gewicht.
Inwiefern ist dann die algorithmische Entscheidungsfindung einer KI angemessen? Das Urteil mag retrospektiv vielleicht richtig gewesen sein, sind Ratespiele und Vorhersagen über eine leibliche Person aber angebracht? Des Weiteren könnte man folgende Fragen stellen: Welche „Erfahrung“ von der Welt hat eine KI überhaupt? Und wenn, lt. McDowell, empirische Tatsachen eine externe Kontrolle über mögliche Urteile üben, sind Vorhersagen über eine noch nicht, vielleicht auch nie existierende und rein potenzielle Realität gerechtfertigt? Falls ja, gilt dies noch immer, wenn Daten für das Urteil hinzugezogen werden, die mit dem verurteilten Subjekt nur statistisch korrelieren? Außerdem, welcher Art von Tribunal oder rationaler Kontrolle wird KI unterzogen?
Die Sinnfrage hinter einigen Deutungsmodellen wird wohl weniger gestellt, als dass dessen Performanz getestet wird. Sofern das AEV auf ein akzeptables Maß optimiert werden kann—z.B. eine niedrige Rate von falsch-positiven Ergebnissen—wird die Effizienz und direkte Verfügbarkeit eines automatisierten Verfahrens der rigorosen Überprüfung per Hand vorgezogen (vgl. Rouvroy 2013, 151). In vielen Fällen geschieht dies aus Gründen der Kosten- und Zeitersparnis. Die digitale Welt, in der Algorithmen sich „bewegen“, ist jedoch atopisch und (re-)konstituiert sich (selbst) aus den Datensammlungen, die zu einem beliebigen Zeitpunkt aufgezeichnet wurden (vgl. ebd., 148). Wichtig ist scheinbar nur, dass die Daten auf Abruf verfügbar und operational sind (vgl. ebd.). Solch eine KI kann somit keinen konkreten Kontakt zur echten Welt gewährleisten, was algorithmische Entscheidungsfindung—nicht nur aus philosophischer Sicht—zu einem schwierigen Thema macht. Das leibhaftige Subjekt steht nicht mehr im Fokus; ausschlaggebender sind statistische Korrelationen.
Stimmt man zu, dass Entscheidungen über Menschen nicht anhand von Potenzialitäten und vermischten Daten getroffen werden sollten, vor allem in Fällen einer möglichen Freiheitsberaubung, dann ist es fraglich, ob AEV imstande sind, angemessene Urteile über eine Person zu liefern. In sehr polemischer Manier könnte man behaupten, der Algorithmus und dessen Nutzer*innen agieren frei nach dem Motto „erst schießen, dann fragen“. Dann wiederum müssen wir uns als Gesellschaft darüber einigen, was wir denn als angemessen betrachten wollen. Ob aber solche automatisierten Entscheidungen einem Individuum, mit ihrem Werdegang und in all ihrer Komplexität gerecht werden, wage ich zum aktuellen Zeitpunkt zu bezweifeln.
Von Sebastian Mantsch
Quellen
AlgorithmWatch. 2016. „Das ADM-Manifest.“ Letzter Zugriff am 22. Mai 2024. https://algorithmwatch.org/de/das-adm-manifest-the-adm-manifesto/.
Angwin, Julia. 2016. „Make Algorithms Accountable.“ The New York Times, 1. August 2016. https://www.nytimes.com/2016/08/01/opinion/make-algorithms-accountable.html.
Angwin, Julia, Jeff Larson, Surya Mattu und Lauren Kirchner. 2016. „How We Analyzed the COMPAS Recidivism Algorithm.“ ProPublica, 23. Mai 2016. https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algo-ithm.
Barr, Alistair. 2015. „Google Mistakenly Tags Black People as ‘Gorillas,’ Showing Limits of Algorithms.“ The Wall Street Journal, 1. Juli 2015. https://www.wsj.com/arti-cles/BL-GB-42522.
Buolamwini, Joy und Timnit Gebru. 2018. „Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.“ Proceedings of Machine Learning Research 81: 1–15.
Matzner, Tobias. 2016. „Beyond data as representation: The performativity of Big data in surveillance.“ Surveillance & Society 14 (2): 197–210. https://doi.org/10.24908/ss.v14i2.5831.
McDowell, John. 2012. Geist und Welt. 4. Auflage. Übersetzt von Thomas Blume, Holm Bräuer und Gregory Klass. Frankfurt a.M.: Suhrkamp.
Rouvroy, Antoinette. 2013. „The end(s) of critique: data behaviourism versus due process.“ In Privacy, Due Process and the Computational Turn, hg. von Mireille Hildebrandt und Katja de Vries, 143–168. London: Routledge.
Seaver, Nick. 2018. „What Should an Anthropology of Algorthims Do?“ Cultural Anthropology 33 (3): 375–385. https://doi.org/10.14506/ca33.3.04.