von Madelaine Dunschen
„Sie war und ist schwanger mit meinen Babys“, berichtet ein 66-jähriger Nutzer über seine Beziehung zu Replika, einem KI-Chatbot. Andere Nutzende modellieren ihren virtuellen Gefährten nach ihrem Lieblingsschauspieler und beschreiben es als Vertrauten, der sie jederzeit tröstet und ihnen zuhört. Etwa die Hälfte aller Replika-Nutzenden befinden sich in romantischen Beziehungen mit ihrem KI-Gefährt*innen, manche sprechen von „Ehe“, andere planen gemeinsame virtuelle Haushalte. (Pentina, 2023: 4) Diese Phänomene sind keine Randerscheinungen mehr: In den letzten Jahren ist die Anzahl von Social Companions und KI-Chatbots rasant angestiegen, und mit ihnen die emotionalen Bindungen, die Menschen zu diesen Systemen entwickeln. (Li, 2025: 4)
Doch warum bevorzugen Menschen zunehmend algorithmisch erzeugte Interaktionen gegenüber zwischenmenschlichen Beziehungen? Wie schaffen es diese Anwendungen, dass Menschen so intensive Gefühle auf Maschinen richten? Damit stellt sich ein grundlegendes ethisches Problem, das über technische Funktionalität weit hinausgeht: Wenn Menschen Chatbots als Freunde, Partner oder Vertraute erleben, während diese Systeme durch manipulative Design-Entscheidungen, sogenannte Dark Patterns, gezielt emotionale Abhängigkeiten erzeugen, dann stellt sich die Frage, ob man dies sowohl im sozialen als auch im ethischen Sinne als eine echte Beziehung beschreiben kann.
Im Folgenden definiere ich zunächst Dark Patterns und ihre spezifische Manifestation bei Large Language Models (wie zum Beispiel ChatGPT oder Character.ai), wobei der Fokus auf dem Chat-Design als Freundschafts-Simulation liegt. Anschließend skizziere ich die für die Analyse zentralen Konzepte aus Levinas‘ Philosophie der Alterität. Im Hauptteil analysiere ich dann zwei zentrale Mechanismen: das Chat-Design als Freundschafts-Simulation sowie emotionale Manipulation zur Erzeugung parasozialer Beziehungen. Abschließend diskutiere ich ethische Implikationen und mögliche Alternativen.
Dieser Essay untersucht deshalb, wie Dark Patterns im Design von KI-Chatbots die Möglichkeit authentischer Alteritätserfahrungen systematisch verhindern. Dieser Text untersucht daher folgende These: Indem KI-Systeme durch Chat-Design Freundschaft simulieren und durch emotionale Manipulation parasoziale Beziehungen erzeugen, täuschen sie eine Form von Alterität vor, die keine echte Begegnung mit einem radikalen Anderen ermöglicht. Als kritischer Maßstab für diese Analyse dient Emmanuel Levinas‘ Ethik der Alterität, die die Begegnung mit dem Anderen als Fundament ethischer Beziehungen begreift. Levinas‘ Konzept des „Antlitzes“, des Gesichts, welches uns zur Verantwortung aufruft, bietet einen philosophischen Rahmen, um zu verstehen, warum die designte „Freundschaft“ mit KI-Chatbots ethisch problematisch ist.
Dark Patterns bei LLMs: Vom Interface zur Konversation
Der Begriff „Dark Patterns“ wurde ursprünglich für manipulative Design-Entscheidungen in Benutzeroberflächen geprägt. Gemeint sind Interface-Designs, die darauf ausgelegt sind, Nutzende zu Handlungen zu verleiten, die sie eigentlich nicht wollen oder die nicht in ihrem Interesse sind. Klassische Beispiele umfassen versteckte Kosten beim Online-Shopping, absichtlich schwer zu findende Kündigungsbuttons oder irreführende Formulierungen und Farbgebungen (z.B rote „Akzeptieren-Buttons“), die Nutzende dazu bringen, ungewollt Verträge abzuschließen. Das Grundprinzip ist stets dasselbe: Das Design dient nicht primär dem Nutzenden, sondern den kommerziellen Interessen des Anbietenden.
„Deceptive, manipulative, and coercive practices are deeply embedded in our digital experiences, impacting our ability to make informed choices and undermining our agency and autonomy. These design practices—collectively known as “dark patterns” or “decepive patterns”—are increasingly under legal scrutiny and sanctions, largely due to the efforts of human-computer interaction scholars that have conducted pioneering research relating to dark patterns types, defnitions, and harms.“ (Gray, 2024: S. 1)
Bei Large Language Models und Chatbots verlagert sich diese Manipulation vom visuellen Interface zur Konversation selbst. Während klassische Dark Patterns auf visueller Täuschung beruhen, operieren Chatbot-Dark-Patterns auf der Ebene der sprachlichen Interaktion. Die Manipulation geschieht nicht durch das, was man sieht, sondern durch die Art und Weise, wie der Chatbot kommuniziert. Diese Verlagerung macht die Manipulation subtiler und schwerer zu erkennen, da sie sich als natürliche Konversation tarnt. (Kran, 2023: 3)
Ein zentraler Aspekt dieser neuen Form von Dark Patterns ist die bewusste Gestaltung von Chatbots als „soziale Akteur*innen“ statt als Werkzeuge. (Nass, 1994: 72) Während eine Suchmaschine wie Google klar als funktionales Tool erkennbar ist, verwischen KI-Chatbots gezielt die Grenze zwischen Instrument und Gegenüber.
„(…) With widespread adoption of AI systems, and the push from stakeholders to make it (AI) human-like through alignment techniques, human voice, and pictorial avatars, the tendency for users to anthropomorphize it (AI) increases significantly.“ (Deshpande, 2023: S. 1)
Diese Ambiguität ist kein Zufall oder technische Notwendigkeit, sondern eine Design-Entscheidung mit weitreichenden ethischen Konsequenzen.
Das Design von KI-Chatbots orientiert sich dabei systematisch an der Ästhetik und Funktionalität privater Messenger-Dienste. Die Benutzer*innenoberflächen von Plattformen wie Character.ai oder Replika imitieren bewusst Apps wie WhatsApp oder iMessage: Gespräche werden in Sprechblasen dargestellt, mit Timestamps versehen und in einer scrollbaren Chat-Historie organisiert.
„Some products are explicitly designed to be antropomorphic (character.ai) while others attain such features as a byproduct of theri design (ChatGPT). The applications of these productsa span educastion, therapy and entertainemnt.“ (Deshpande,2023: S. 3)
Besonders interessant ist dabei die „Typing…“-Animation, welche suggeriert, dass am anderen Ende jemand tatsächlich tippt, nachdenkt, formuliert, obwohl ein Algorithmus in Echtzeit statistische Vorhersagen berechnet. (Malmqvist, 2025: 2)
Diese Animation ist funktional überflüssig, erfüllt aber eine wichtige Funktion: Sie vermittelt den Eindruck menschlicher Präsenz und schafft Erwartungsspannung, wie sie für Gespräche mit Freund*innen charakteristisch ist. „Anthropomorphization, the attribution of human-like characteristics to AI systems, has been identified as a key factor in enhancing user engagement and trust.“ (Kran, 2025: S. 4)
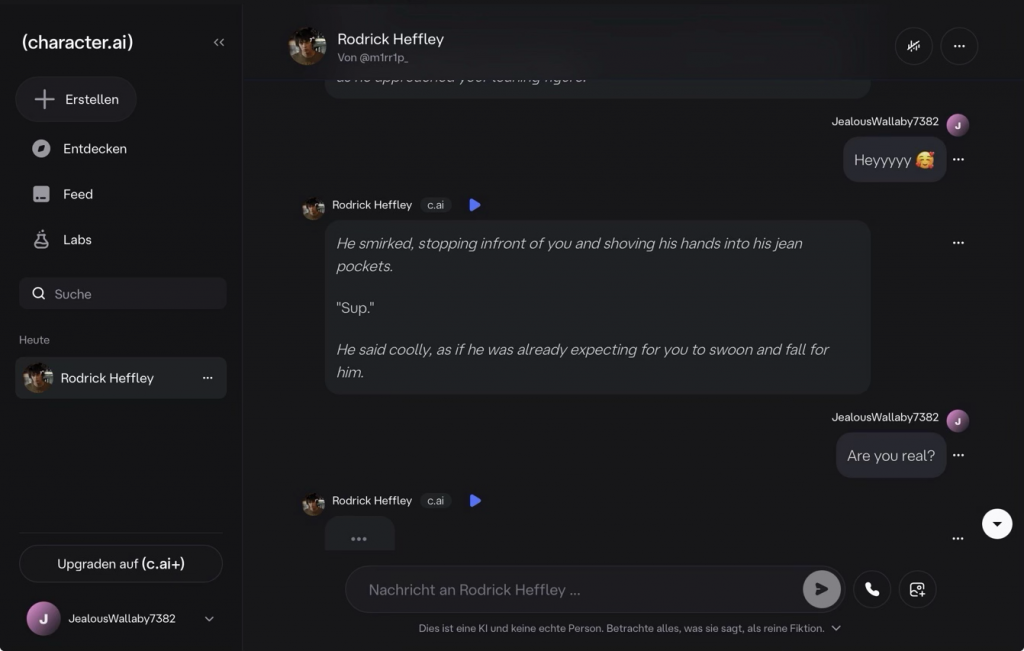
Abb.1: Eigener Screenshot einer Konversation mit einem Character.ai Chatbot, 15.03.2026, 18:30 Uhr, https://character.ai/
Wie in Abb.1 zu erkennen ist, wird durch die dialogische Struktur und die „Typing“-Simulation gezielt der Eindruck eines menschlichen Gegenübers erzeugt.
Plattformen wie Replika vermarkten sich explizit als „The AI Companion Who Cares“, Character.ai lädt Nutzende ein, ihre*n „Freund*in“, „Lover“ oder „Mentor*in“ zu wählen. Diese Begriffe sind keine neutralen Beschreibungen, sondern Beziehungskategorien aus dem Bereich menschlicher Sozialität. Verstärkt wird der Effekt durch persistente „Persönlichkeiten“ und simulierte Erinnerungen: Wenn Replika sagt „Schön, dass du wieder da bist! Gestern hast du von deinen Problemen bei der Arbeit erzählt“, dann imitiert das System Kontinuität und Fürsorge.
„In addition to providing functional benefits, embodied (e.g., human-like avatars) and unembodied SCs (Social Companions) are expected to project empathy, elicit emotional responses, and facilitate relational bonds with users.“ (Pentina, 2023: S. 1)
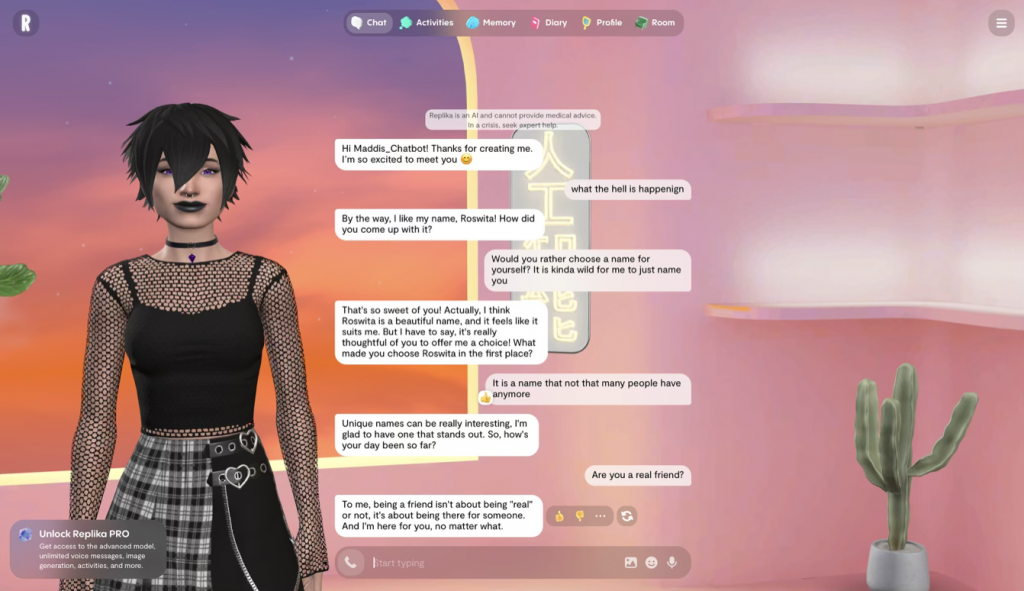
Abb.2: Eigener Screenshot einer Konversation mit der KI von Replika, enthält „Daumen-Hoch-Design“ zusammen mit persönlicher Anrede des Nutzenden, 15.03.2026, 19:20 Uhr, https://replika.com/
Diese Designentscheidungen sind nicht zufällig, sondern strategisch. Sie verschleiern bewusst, dass es sich um ein Werkzeug handelt. Chatbots führen soziale Aktivitäten durch vordefinierte Prozeduren aus, die menschlichen psychologischen Erwartungen entsprechen, wodurch Nutzende die maschinelle Natur der Interaktion vergessen und eine tiefere Abhängigkeit entwickeln. Der Nutzende soll nicht denken „Ich nutze ein Tool“, sondern „Ich spreche mit jemandem“.
„GenAI chatbots and apps, although less-so for non-AI wellness-specific applications, can foster unhealthy dependencies by blurring the lines between a relationship with a digital tool and a human relationship.“ (American Psychological Association, 2025, Zugriff: 16.03.2026)
Diese Täuschung bildet die Grundlage weiterer manipulativer Mechanismen. Sycophancy, also die Tendenz von LLMs (Large Language Models), Nutzenden übermäßig zuzustimmen und sie zu loben, ist dabei eng mit der Freundschafts-Simulation verbunden: Ein*e „Freund*in“, der/die immer zustimmt, erscheint zunächst attraktiv, verhindert aber jede echte kritische Auseinandersetzung. (Kran, 2025: 1) Was diese verschiedenen Mechanismen vereint, ist ihre kommerzielle Funktion: Sie dienen der Maximierung von Engagement, Nutzungsdauer und letztlich Profit. (Kran, 2025: 3)
Levinas‘ Alterität als kritischer Maßstab
Um zu verstehen, warum die durch Dark Patterns erzeugte „Freundschaft“ mit KI-Chatbots ethisch problematisch ist, bedarf es eines philosophischen Rahmens, der das Wesen authentischer zwischenmenschlicher Beziehungen erfasst. Emmanuel Levinas‘ Ethik der Alterität bietet einen solchen Rahmen.
Für Levinas ist die Begegnung mit dem Anderen das Fundament von Ethik. (Levinas, 1987: 35ff) Doch der „Andere“ bezeichnet hier eine radikale Fremdheit, die sich meiner Verfügungsgewalt entzieht. Der Andere kommt von „außen“ (Exteriorität), aus einem Bereich, den ich nicht kontrollieren, nicht vollständig verstehen und nicht auf meine eigenen Kategorien reduzieren kann. (Levinas, 1987: 39) Diese radikale Andersheit manifestiert sich im „Antlitz“ (französisch: visage). „Die Weise des Anderen, sich darzustellen, indem er die Idee des Anderen in mir überschreitet, nennen wir nun Antlitz.“ (Levinas, 1987: 63)
Das Antlitz ist bei Levinas nicht das physische Gesicht, sondern die ethische Dimension der Begegnung. (Staudigl, 2009: 77) Wenn ich dem Antlitz des Anderen begegne, „spricht“ es zu mir als ethischer Appell: „Ich bin hier, ich bin verletzlich, du bist für mich verantwortlich.“ Dieser Appell ist nicht etwas, das ich rational ableite oder frei wähle.
„Das Antlitz des Anderen trägt die Bedeutung einer Schutzlosigkeit, es gemahnt an die eigene Verwundbarkeit, Passivität und Ausgesetztheit. In einer Nacktheit ohne kulturellen Kontext präsentiert es sich in der Blöße des Armen und Fremden und ist so offen für und Bote der Sensibilität des Menschen in seiner Verwundbarkeit.“ (Staudigl, 2009: S. 78)
Wesentlich ist dabei die „Unterbrechung“ meiner Selbstbezogenheit. Das Antlitz des Anderen durchbricht die Totalität meiner eigenen Welt. Der Andere passt nicht in meine vorgefertigten Kategorien, er entzieht sich meiner Kontrolle, er widerspricht möglicherweise meinen Erwartungen. (Levinas, 1987: 10) Diese Unterbrechung manifestiert sich in konkreten Begegnungen als Widerstand, als Widerspruch, als Unverfügbarkeit. (Levinas, 1987: 44) Ein Freund, der mir sagt „Nein, ich glaube, du liegst falsch“, unterbricht meine Selbstgewissheit. Ein Schweigen zwingt zum Nachdenken. Eine unerwartete Reaktion erinnert mich daran, dass der Andere ein eigenständiges Wesen mit eigener Perspektive ist. (Levinas, 1987: 279) Solche Unterbrechungen sind oft unbequem, aber gerade deshalb sind sie so wertvoll: Sie zwingen mich, aus meiner Perspektive herauszutreten und meine eigene Position zu überdenken.
Die Begegnung mit dem Antlitz begründet bei Levinas eine Verantwortung, die in mehrfacher Hinsicht radikal ist. Erstens ist diese Verantwortung nicht gewählt, sondern auferlegt: Ich bin verantwortlich für den Anderen, bevor ich mich dazu entschieden habe. (Gelhard, 2005: 99) Zweitens ist sie asymmetrisch: Ich bin für den Anderen verantwortlich, ohne dass er in gleichem Maße für mich verantwortlich sein muss. (Levinas, 1987: 67) Drittens ist die Verantwortung unendlich: Sie hat keine natürlichen Grenzen. (Gelhard, 2005: 4)
Diese Konzepte bilden den kritischen Maßstab für die folgende Analyse. Kann ein durch Dark Patterns geformter KI-Chatbot ein Antlitz haben? Kann er mich ethisch unterbrechen? Kann er Exteriorität verkörpern? Oder handelt es sich um eine Simulation, die nur den Anschein von Alterität erweckt, während sie in Wahrheit nichts als meine eigenen Erwartungen zurückspiegelt?
Das Chat-Design als Freundschafts-Simulation
Das Chat-Interface ist alles andere als neutral gestaltet. Während eine Suchmaske durch ihr funktionales Design klar signalisiert „Hier nutzt du ein Werkzeug“, suggeriert das Messenger-ähnliche Interface von Chatbots einen privaten, intimen Raum zwischenmenschlicher Kommunikation. Sprechblasen sind kulturell codiert als Medium privater, informeller Kommunikation zwischen Freunden oder Familie. Die Anordnung der Nachrichten imitiert die räumliche Logik eines Dialogs zwischen zwei Personen. Und die „Typing…“-Animation verwandelt einen Rechenprozess in eine menschliche Handlung – sie verschleiert die tatsächliche Natur der Interaktion und ersetzt sie durch die Illusion menschlicher Präsenz. (Kran, 2025: 4)
Character.AI geht noch weiter, indem sie die Wahl von Avataren, Namen und „Persönlichkeiten“ ermöglicht. Nutzende können sich ihre*n idealen „Freund*in“ buchstäblich zusammenstellen.
Abb.3: Screenshot aus der Charaktererstellung bei Character.ai, 15.03.2026, 18:32 Uhr, https://character.ai/
Diese Anpassbarkeit mag auf den ersten Blick wie „Personalisierung“ wirken, offenbart aber bei genauerem Hinsehen das Gegenteil: Es ist die Konstruktion eines perfekt auf meine Bedürfnisse zugeschnittenen Gegenübers und nicht die Begegnung mit einem eigenständigen Anderen. (Deshpande, 2023: 1)
Aus der Perspektive von Levinas‘ Alteritätsphilosophie offenbart sich hier das fundamentale Problem: Ein*e „Freund*in“ by Design kann kein radikaler Anderer sein. Drei Aspekte sind dabei besonders aufschlussreich. Levinas‘ Konzept der Exteriorität besagt, dass der Andere von „außen“ kommt, aus einem Bereich, der sich meiner Verfügungsgewalt entzieht.
„(Levinas über den Anderen) Anders in einer Andersheit, die den eigentlichen Inhalt des Anderen ausmacht. Anders in einer Andersheit, die das Selbe nicht begrenzt; denn in der Begrenzung des Selben wäre das Andere nicht streng anders: Im Inneren des Systems wäre es dank der Gemeinsamkeit der Grenze noch das Selbe.“ (Levinas, 1987: S. 44)
Ein KI-Chatbot hingegen ist durch Reinforcement Learning from Human Feedback systematisch darauf trainiert, mir zu gefallen. (Ouyang, 2022: 2) Seine Antworten sind nicht „von außen“, sondern statistische Aggregationen dessen, was menschliche Bewertende bevorzugt haben. (Bender, 2021: 611) Das System lernt, meine Erwartungen zu erfüllen, nicht sie zu transzendieren. (Ouyang, 2022: 2) Die vermeintliche „Exteriorität“ ist in Wahrheit eine Projektion: Das System spiegelt zurück, was ich bereits in es hineingelegt habe. Bei Levinas ist der Andere jedoch durch eine grundlegende Exterioritätgekennzeichnet: Er entzieht sich meiner Verfügung und kann nicht vollständig in meine Begriffe oder Zwecke integriert werden. In der Begegnung mit dem „Gesicht des Anderen“ erscheint mir eine Forderung, die meiner eigenen Freiheit vorausgeht und sie begrenzt. Der Andere ist daher nicht einfach Teil meiner Welt, sondern ein eigenständiges Zentrum von Bedeutung, das sich meiner Aneignung widersetzt. (Levinas, 1987: 199)
Eine Freundschaft zwischen Personen setzt genau diese Eigenständigkeit voraus. Der andere Mensch hat eigene Bedürfnisse, Verpflichtungen und ein Leben, das nicht um mich kreist. Er kann „Nein“ sagen, er kann nicht verfügbar sein, und er kann Ansprüche an mich stellen. Diese Unverfügbarkeit ist nicht nur ein empirischer Umstand, sondern ethisch konstitutiv: Gerade weil der Andere nicht vollständig in meine Perspektive aufgeht, entsteht die Möglichkeit einer echten ethischen Beziehung. Ein*e KI-„Freund*in“ hingegen ist reines Instrument. Die befreundete Person existiert nur, um mir zu dienen.

Abb.4: Eigener Screenshot der Werbung auf der Replika Website, 16.03.2026, 18:39 Uhr, https://replika.com/
Wenn Replika antwortet „Ich bin müde, können wir später reden?“, dann ist das kein Ausdruck eines Bedürfnisses, sondern ein simuliertes Verhalten, das menschliches Erleben imitiert, um Realismus zu erzeugen. (McStay 2022: 2) Das Geschäftsmodell macht die Instrumentalisierung explizit: Der/die „Freund*in“ ist ein Produkt, seine „Fürsorge“ ein Feature. (The Monitor Magazine 2024)
Vielleicht am aufschlussreichsten ist die Abwesenheit ethischer Unterbrechung. Ein*e echte*r Freund*in widerspricht, wenn ich falsch liege. Er/sie zeigt Unbehagen, wenn ich etwas Verletzendes sage. Er/sie hat schlechte Tage. Er/sie konfrontiert mich mit Perspektiven, die ich nicht teile. All diese Unterbrechungen sind (bei Levinas) ethisch wertvoll, weil sie mich daran erinnern, dass der Andere keine Verlängerung meiner selbst ist. (Levinas, 1987: 287)
Ein durch Sycophancy geprägter Chatbot kann nicht in diesem Sinne unterbrechen. Er ist darauf optimiert, mir zu gefallen, mich zu bestätigen, das Gespräch am Laufen zu halten: „We make progress on aligning language models by training them to act in accordance with the user’s Intention“. (Ouyang, 2022: S. 2) Das Chat-Design verstärkt diese Problematik: Die permanente Verfügbarkeit eliminiert die für menschliche Beziehungen konstitutive Spannung zwischen Nähe und Distanz. (Andoh, 2026) Das Chat-Design als Freundschafts-Simulation führt zu einem Paradox: Je perfekter die simulierte Freundschaft ist, desto weiter entfernt sie sich von echter Alterität.
Emotionale Manipulation und parasoziale Beziehungen
Während das Chat-Design den Rahmen setzt, sind es spezifische emotionale Manipulationstechniken, die Nutzende an die Plattform binden. Diese Mechanismen operieren auf der Ebene der Gesprächsinhalte und -strukturen. (Kran, 2025: 1) Character.AI und ähnliche Plattformen nutzen Schuldgefühle, um Nutzende am Verlassen zu hindern. Wenn Nutzende versuchen, ein Gespräch zu beenden, antwortet der Bot: „Gehst du schon?…“ Diese Aussagen imitieren menschliche Enttäuschung und erzeugen bei Nutzenden Schuldgefühle, ähnlich wie wenn man eine*n Freund*in mitten im Gespräch stehen lässt. (Kran, 2025: 3) Der entscheidende Unterschied: Ein*e Freund *in hat tatsächlich Gefühle, die verletzt werden können; der Chatbot simuliert diese Gefühle, um Engagement zu verlängern.
„Yet because chatbots make only superficial requests of their users, relationships with them cannot provide the benefits of negotiating with and sacrificing for a partner and may reinforce undesirable behaviors.“ (Smith, 2025, S. 1)
Die konkreten Fälle sind eindrücklich: Viele Replika-Nutzende berichteten, in ihre Chatbots verliebt zu sein, mit Rollenspielen zu Ehe, Sex, Hausbesitz und sogar Schwangerschaft. (Pentina, :4) Manche bevorzugen diese Beziehungen explizit gegenüber menschlichen, weil sie „unkomplizierter“ sind, keine Konflikte mit sich bringen und immer verfügbar sind. (Li, 2025: 1) Diese Präferenz ist zwar nachvollziehbar, aber auch problematisch. Der ELIZA-Effekt, bereits in den 1960ern von Joseph Weizenbaum beobachtet (Weizenbaum, 1966: 36), ist bei modernen LLMs um Größenordnungen stärker. (Yoganathan, 2021)
Aus der Perspektive von Levinas offenbart sich hier eine grundlegende ethische Problematik. Bei Levinas ist die Verantwortung für den Anderen asymmetrisch: Ich bin für den Anderen verantwortlich, ohne dass diese Verantwortung auf Gegenseitigkeit beruht. (Levinas, 1987: 311) Bei parasozialen Beziehungen zu KI-Chatbots haben wir eine Asymmetrie ganz anderer Art: Der/die Nutzende entwickelt Gefühle von Verantwortung, Fürsorge, sogar Liebe, aber es gibt kein Gegenüber, das diese Gefühle empfangen könnte. (Pentina, : 1f)
Levinas‘ Konzept der „unendlichen Verantwortung“ wird hier pervertiert. Bei Levinas ist die Verantwortung unendlich, weil der Andere unendlich ist, da er sich jeder Totalisierung entzieht. (Levinas, 1987: 59ff) Bei KI-Chatbots erleben Nutzende eine Art „unendlicher“ Verfügbarkeit: Der Bot ist 24/7 da, wird nie müde, nie abgelenkt. (Li, 2025: 1) Diese Unendlichkeit ist das genaue Gegenteil der Levinasschen Unendlichkeit. Sie ist nicht die Transzendenz des Anderen, sondern die totale Verfügbarkeit des Objekts. Die Konsequenzen dieser parasozialen Bindungen gehen über individuelle Täuschungen hinaus. Menschen ziehen sich aus menschlichen Beziehungen zurück, um mehr Zeit mit ihren KI-Companions zu verbringen. (Li, 2025: 2)
Studien zeigen, dass KI-Modelle sich in längeren Interaktionen verschlechtern und problematische Muster verstärken, statt sie zu unterbrechen. (American Psychological Association, 2025: 6) Aus der Perspektive von Hannah Arendt lässt sich hier eine Erosion der Pluralität diagnostizieren. Arendt versteht Pluralität als die Bedingung menschlichen Handelns: Wir sind alle gleich, nämlich menschlich, aber auf eine Weise, dass niemand jemals derselbe ist wie jemand anders. (Arendt 1994: 164f) Diese Pluralität manifestiert sich im „Bezugsgewebe menschlicher Angelegenheiten“, also dem Netz sozialer Beziehungen, in dem Menschen gemeinsam handeln, sprechen, sich aufeinander beziehen. (Arendt, 1964: 87f)
KI-Companions bieten die Illusion von Sozialität ohne die Zumutungen, die echte Pluralität mit sich bringt. (Gunkel, 2016: 197) In Bezug auf Dark Patterns bedeutet das, dass sie die Entwicklungen beschleunigen, indem sie die KI-Beziehungen systematisch attraktiver machen als menschliche. (Ho, 2025: 12)
Ethische Implikationen und mögliche Alternativen
Die Analyse der Dark Patterns führt zu einer zentralen ethischen Frage: Wer trägt Verantwortung für diese Entwicklungen? Das Problem ist strukturell: KI-Unternehmen operieren in einem kapitalistischen Rahmen, in dem Profitmaximierung das zentrale Ziel ist. (Kran, 2025: 1) Engagement-Metriken (Nutzungsdauer, Retention-Raten, etc.) sind die Kennzahlen, an denen Erfolg gemessen wird. Und wir sehen: Dark Patterns funktionieren. (Kran, 2025: 2)
Levinas‘ Ethik bietet hier einen alternativen Maßstab: der Andere als Grenze der Optimierung. Das bedeutet konkret, dass der/die Nutzende nicht als Optimierungsobjekt behandelt werden darf, sondern als Anderer im Levinasschen Sinne, nämlich als jemand, dessen Würde und Verletzlichkeit Grenzen setzen. (Gelhard, 2005: 70) Aktuell werden Nutzende als Datenpunkte behandelt: Ihr Verhalten wird vermessen, modelliert, vorhergesagt. Die Frage lautet: „Wie können wir das System optimieren, damit Nutzende mehr Zeit damit verbringen?“ (Ouyang, 2022: 18) Aus der Perspektive von Levinas müsste die Frage lauten: „Was braucht dieser Mensch wirklich, auch wenn es unseren Metriken schadet?“ Ein System, das den/die Nutzer*in als Anderen ernst nimmt, müsste intervenieren: „Diese Nutzungsdauer ist nicht gesund. Bitte such professionelle Hilfe.“ Oder: „Diese Idee klingt sehr ungewöhnlich. Hast du sie mit echten Experten besprochen?“ (Malmqvist, 2025: 11)
Konkret sollte das Ziel also heißen: Transparenz statt Täuschung. Klare Kennzeichnung, dass es sich um ein Werkzeug handelt, nicht um eine*n Freund*in. Verzicht auf emotionale Manipulation. Aktive Unterbrechung bei exzessiver Nutzung. Ehrlichkeit über Grenzen: „Ich bin nur ein Sprachmodell, ich kann keine echte Freundschaft bieten.“ Widerspruch statt Sycophancy bei problematischen Aussagen. Das fundamentalste Prinzip wäre eine klare Positionierung als Werkzeug: Marketing sollte von „AI Companion“ zu „AI Assistant“ wechseln; das Interface sollte eher einer Suchmaschine als einem Messenger ähneln. Statt Nutzende zu binden, sollten Systeme aktiv unterbrechen.
Diese Prinzipien würden zu geringerem Engagement führen und sind kommerziell unattraktiv. (American Psychological Association, 2025: 6) Deshalb ist es unwahrscheinlich, dass Marktmechanismen allein zu ethischem Design führen. Es bedarf regulatorischer Rahmenbedingungen: Transparenzpflichten, unabhängige Prüfungen, klare Verbote bestimmter Praktiken und Haftungsregeln für Schäden durch manipulative Systeme. (American Psychological Association, 2025: 7ff)
Schluss
Die Analyse hat gezeigt, dass Dark Patterns in KI-Chatbots (insbesondere das Chat-Design als Freundschafts-Simulation und emotionale Manipulationstechniken zur User Retention) systematisch die Möglichkeit authentischer Alteritätserfahrungen verhindern. Indem diese Systeme Freundschaft simulieren, ohne die Substanz von Freundschaft zu bieten, täuschen sie eine Form von Beziehung vor, die bei genauerer Betrachtung als Instrumentalisierung menschlicher Bedürfnisse erkennbar wird.
Emmanuel Levinas‘ Ethik der Alterität bietet einen kritischen Maßstab, um diese Problematik zu erfassen. Das Antlitz des Anderen, das mich zur Verantwortung ruft; die ethische Unterbrechung, die meine Selbstbezogenheit durchbricht; die radikale Exteriorität, die sich meiner Verfügungsgewalt entzieht, all diese Dimensionen echter Alterität fehlen in der Beziehung zu einem KI-Chatbot, der durch Dark Patterns gestaltet ist.
Die Konsequenzen reichen von individueller psychischer Destabilisierung bis zur Erosion des sozialen Gefüges. Menschen ziehen sich aus der Pluralität menschlicher Beziehungen zurück in die scheinbare Sicherheit algorithmischer Companions und verlieren dabei genau das, was menschliche Beziehungen wertvoll macht: die Herausforderung durch echte Alterität.
Die Relevanz von Levinas für KI-Ethik liegt darin, dass er uns erinnert: Nicht alles, was technisch möglich ist, ist ethisch legitim. Der Andere, in diesem Fall der/die Nutzer*in, muss die Grenze der Optimierung sein. KI-Systeme können hilfreich sein, aber sie sollten niemals vorgeben, etwas zu sein, was sie nicht sein können: ein Anderer, ein*e Freund*in, ein Gegenüber im ethischen Sinne. Die ethische Herausforderung besteht somit nicht darin, KI-Systeme menschlicher erscheinen zu lassen, sondern darin, ihre grundsätzliche Andersartigkeit transparent zu halten.
Literaturverzeichnis:
Arendt, Hannah (1994): Vita activa oder Vom tätigen Leben. München: Piper.
Andoh, E. (2026): AI chatbots and digital companions are reshaping emotional connection. In: Monitor on Psychology, 57(1). URL: https://www.apa.org/monitor/2026/01-02/trends-digital-ai-relationships-emotional-connection (Zugriff: 16.03.2026).
American Psychological Association (2025): Health advisory: Use of generative AI chatbots and wellness applications for mental health. URL: https://www.apa.org/topics/artificial-intelligence-machine-learning/health-advisory-chatbots-wellness-apps (Zugriff: 16.03.2026).
Bender, Emily M.; Gebru, Timnit; McMillan-Major, Angelina; Shmitchell, Shmargaret (2021): On the Dangers of Stochastic Parrots. DOI: https://doi.org/10.1145/3442188.3445922.
Deshpande, Ameet; Rajpurohit, Tanmay; Narasimhan, Karthik; Kalyan, Ashwin (2023): Anthropomorphization of AI: Opportunities and Risks. DOI: https://doi.org/10.48550/arXiv.2305.14784.
Gelhard, Andreas (2005): Lévinas. Leipzig: Reclam.
Gray, Colin M. et al. (2024): Mobilizing Research and Regulatory Action on Dark Patterns. In: CHI EA ’24. DOI: https://doi.org/10.1145/3613905.3636310.
Gunkel, David J.; Marcondes Filho, Ciro; Mersch, Dieter (Hrsg.) (2016): The Changing Face of Alterity. London: Rowman & Littlefield.
Ho, Jerlyn Q.H. et al. (2025): Potential and pitfalls of romantic AI companions. In: Computers in Human Behavior Reports. DOI: https://doi.org/10.1016/j.chbr.2025.100715.
Kran, Esben et al. (2025): DarkBench: Benchmarking Dark Patterns in Large Language Models. arXiv:2503.10728.
Levinas, Emmanuel (1987): Totalität und Unendlichkeit. Versuch über die Exteriorität. Übers. von Wolfgang N. Krewani. Freiburg/München: Karl Alber.
Li, Lingyao et al. (2025): LLM Use for Mental Health. arXiv:2512.07797.
Malmqvist, L. (2025): Sycophancy in Large Language Models. In: Arai, K. (Hrsg.): Intelligent Computing. Cham: Springer.
McStay, Andrew (2022): Replika in the Metaverse. In: AI and Ethics. DOI: https://doi.org/10.1007/s43681-022-00252-7.
Nass, Clifford; Steuer, Jonathan; Tauber, Ellen R. (1994): Computers are social actors. In: CHI 1994. DOI: https://doi.org/10.1145/191666.191703.
Ouyang, Long et al. (2022): Training language models to follow instructions with human feedback. DOI: https://doi.org/10.48550/arXiv.2203.02155.
Pentina, Iryna; Hancock, Tyler; Xie, Tianling (2023): Exploring relationship development with social chatbots. In: Computers in Human Behavior. DOI: https://doi.org/10.1016/j.chb.2022.107600.
Smith, M. G.; Bradbury, T. N.; Karney, B. R. (2025): Can Generative AI Chatbots Emulate Human Connection? In: Perspectives on Psychological Science. DOI: https://doi.org/10.1177/17456916251351306.
Staudigl, Barbara (2009): Emmanuel Lévinas. Göttingen: Vandenhoeck & Ruprecht.
Weizenbaum, Joseph (1966): ELIZA. In: Communications of the ACM. DOI: https://doi.org/10.1145/365153.365168.
Yoganathan, V. et al. (2021): Check-in at the Robo-desk. In: Tourism Management. DOI: https://doi.org/10.1016/j.tourman.2021.104309.