Ein weiterer Themenpunkt im Rahmen der Spring School umfasste die Erstellung von Datenbanken mittels Datenbankmanagementsystemen. Zwar bieten auch Excel und Word prinzipiell die Möglichkeit einer Datenerfassung und –verwaltung, doch können in speziellen Datenbankmanagementsystemen wie Access oder MySQL Relationen und Datenausgaben besser strukturiert und effizienter genutzt werden. So können Daten verschiedener Tabellen gezielt miteinander verknüpft werden, was Redundanzen verhindert. Dadurch wird eine größere Übersichtlichkeit erzielt und zugleich weniger Datenspeicher verbraucht. Insbesondere bei großen Datenmengen ist ein solches Datenbankmanagementsystem von Vorteil.
In unserem Kurs haben wir MS Access genutzt, das wahrscheinlich zu den bekanntesten Programmen in diesem Bereich zählt. Am Beispiel eines Bibliothekssystems wurde die Erstellung einer relationalen Datenbank veranschaulicht. Als Übung erhielten wir die Aufgabe, eine einfache Tabelle in eine Datenbank zu überführen. In der Tabelle wurden Personendaten aus der Zeit des Nationalsozialismus festgehalten. Neben Name sowie Geburts- und Sterbedatum wurde außerdem, wenn vorhanden, eine Mitgliedschaft in einer NS-Institution erfasst. Lag eine Mitgliedschaft vor, wurden Eintrittsdaten und Parteiort angegeben.
Um diesen Datenbestand effizient in einer Datenbank nutzbar zu machen, musste zuerst eine Normalisierung erfolgen. In einem ersten Schritt habe ich das Attribut „Name“ in der Tabelle atomisiert, also in mehrere Spalten aufgeteilt. In diesem Fall sind dies Vor- und Nachname. Ein weiteres Problem stellte sich bei den Attributen „Institution“ und „Eintrittsdatum“. Hier konnten mehrere Werte in einem Datenfeld stehen. Um dies zu übersichtlicher zu gestalten, hätte man für jeden Wert einen eigenen Datensatz anlegen können. Dies würde jedoch bedeuten, dass Mitglieder von zwei oder drei Institutionen mehrmals in der Tabelle auftauchen. Zudem gibt es auch Personen in der Tabelle, die keiner NS-Organisation Mitglied waren. Diese Doppeleinträge kann man vermeiden, wenn man eine eigene Tabelle für die Institutionen anlegt.

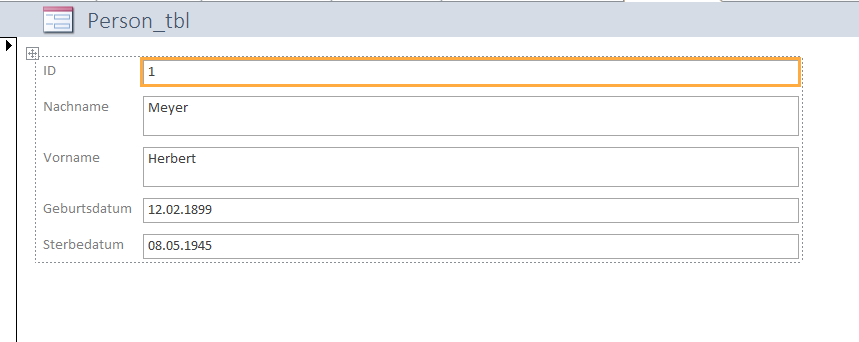
Die von mir erstellte Tabelle Person_tbl erhält lediglich die Daten zu den Personen und gibt diesen jeweils eine ID. Vor- und Nachname erhielten eigene Spalten.
Es ergaben sich jedoch weitere Problemstellungen: So ist bei dem zweiten Datensatz (Manfred Schmidt) lediglich die SA als Mitgliedschaft eingetragen, in der Spalte „Eintrittsdatum“ ist jedoch das NSDAP-Aufnahmedatum verzeichnet. Ich kann mir dies durch den Verlust von entsprechendem Quellenmaterial erklären. Für eine intensivere Auseinandersetzung müsste man sich genauer mit den Quellen, aber auch mit dem institutionellen Aufbau der NSDAP und seinen Verbänden beschäftigen. Eine weitere Frage stellt sich mir beim Attribut „Parteiort“. Bezieht sich dieser nur auf die NSDAP oder sind auch SS und SA den jeweiligen Parteiorten zugeordnet. Hier liegen zudem logischerweise auch nur bei Mitgliedern der NS-Organisationen Eintragungen vor. Ich habe mich dazu entschieden, eine dritte Tabelle zu erstellen, in welcher ich die ID der Personen mit den Parteiorten verbunden und diese jeweils mit einer eigenen ID versehen habe. In einer vierten Tabelle habe ich dann die Parteimitglieder-Parteiort-ID mit der ID der Institutionen verbunden und zusätzlich das Eintrittsdatum in einem weiteren Feld verzeichnet. So konnte ich alle Informationen bzw. Daten erhalten und auf Redundanzen verzichten.

Grafische Darstellung der Beziehungen zwischen den Tabellen. Die Verbindungen wurden durch die ID-Schlüssel hergestellt. (Klicken Sie auf das Bild, um es zu vergrößern.)
Die einzelnen Tabelleneintragungen lassen sich auch übersichtlich als Formulare anzeigen. Hier sehen Sie das Access-Formular zu den Daten von Herbert Meyer: