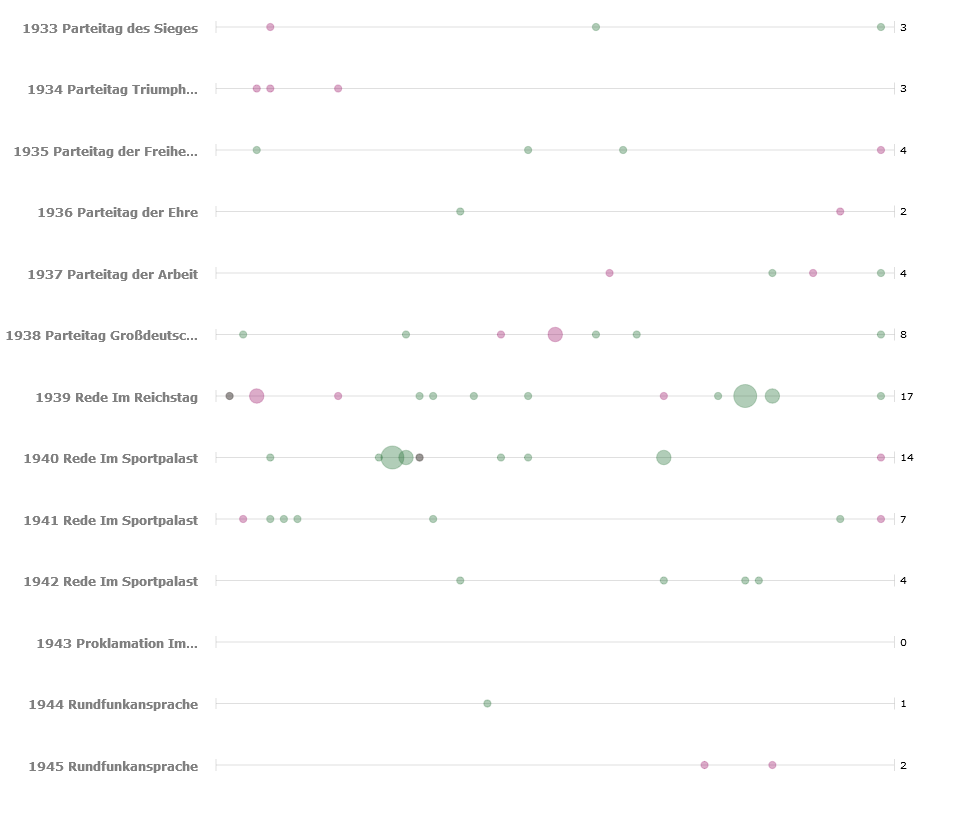
Um uns mit den technischen Voraussetzunge der Digitalisierung vertraut zu machen, sollten wir den Aufsatz „Digitalisierung“ von Malte Rehbein lesen. Rehbein beschäftigt sich hier mit der kultur- und geisteswissenschaftlichen Nutzbarmachung von Digitalisaten. Zugleich werden auch die Anforderungen an die digitalen Kopien thematisiert.
Rastergrafik
Der Autor konzentriert sich dabei vor allem auf die digitale Abbildung von optischen Informationsträgern, also Bild- und Textquellen. Die Erfassung gelingt dabei durch Sensoren, die das reflektierte Licht registrieren und in digitale Daten umwandeln. Es entsteht eine Rastergrafik als digitale Kopie.
Dabei werden innerhalb eins Koordinatensystems alle Bildpunkte (Pixel) mit ihrer jeweiligen Farbtiefe erfasst. Die Farbtiefe ergibt sich aus dem Bitcode. Je mehr Bits zur Beschreibung eines Pixels vorhanden sind, desto größer ist die Farbauswahl. Die Farbtiefe der einzelnen Bildpunkte und die Zahl der Pixel bilden die Werte einer Rastergrafik und machen daher auch den Speicherbedarf aus. So können große Bilder mit einer Vielzahl an Farben viel Speicherplatz und eine hohe Rechenleistung erfordern. Mittels Kompressionsverfahren lässt sich die Dateigröße jedoch vermindern. Viele standardmäßig genutzte Kompressionsformate sind jedoch verlustbehaftet: Um Speicherplatz zu sparen, werden vom menschlichen Auge nicht wahrnehmbare Differenzierungen und Eindrücke aus dem Bild herausgefiltert. Bei einer zu hohen Kompression ist jedoch eine visuelle Verschlechterung des Bildes zu erkennen. Daneben gibt es auch verlustfreie Kompressionsverfahren. Dabei werden Redundanzen vermieden, indem zusammenhängende Bildpunkte mit derselben Farbtiefe nur einmal als Pixel gespeichert werden. Gleichzeitig werden die Informationen über die genauen Koordinaten der Bildpunkte durch einen Algorithmus gespeichert. Dieses Verfahren bedeutet zwar einen geringeren Speicherverbrauch, verlangt jedoch eine höhere Rechenleistung, da das Bild bei jeder Darstellung entsprechend gerastert werden muss.
Vektorgrafik
Neben den Rastergrafiken finden vor allem Vektorgrafiken Verwendung. Hier werden nicht die einzelnen Bildpunkte gespeichert, sondern Informationen zu den geometrischen, farblichen und weiteren gestalterischen Eigenschaften. Bei der Ausgabe der Grafik wird das Bild anhand dieser Informationen mit einem Algorithmus berechnet. Der große Vorteil besteht darin, dass sich Vektorgrafiken ohne Qualitätsverlust skalieren lassen. In der Regel ist der Speicherbedarf auch geringer, da nur die Parameter gespeichert werden. Im Gegenzug benötigt man für das Aufrufen einer Vektorgrafik jedoch mehr Rechenleistung, da das Bild erst gerendert werden muss. Der Speicherplatz einer Vektorgrafik richtet sich daher auch nicht nach der Größe des Bildes oder der Farbtiefe, sondern nur nach der Komplexität der Darstellung. Aufgrund der technischen Komplexität werden Bilder und Texte jedoch meist als Rastergrafiken digitalisiert.
Parameter
Die technischen Parameter bestimmen die Qualität des Digitalisats und damit auch die wissenschaftliche Aussagekraft. Es gibt hier keine allgemeingültigen Vorgaben. Vielmehr muss bei der Einstellung der technischen Parameter die spätere Nutzung und der Forschungszweck mitbedacht werden. Aus diesem Grund ist es wichtig, die technischen Parameter der jeweiligen Digitalisierung zu kennen. Nur so kann man feststellen, ob sich die digitalen Abbilder überhaupt für den jeweiligen Forschungszweck eignen.
Trotzdem gibt es einige allgemeine Richtlinien, die vor allem die Auflösung des Digitalisats betreffen. Diese sollte mindestens 300 dpi (dots per inch) betragen. Ein inch sind 25,4 mm, sodass mindestens 300 Pixel auf einer 25,4 mm langen Strecke abgetastet werden sollten. Bei detaillierten Untersuchungen einzelner Bildteile oder des Materials sind noch höhere Auflösungen notwendig.
Geräte zur Digitalisierung und Archivierung
Die Standardgeräte zur Digitalisierung sind dabei Scanner und Digitalkameras. Beide arbeiten mit elektronischen Bildsensoren, die das reflektierte Licht auffangen und in ein Abbild umwandeln. Verwendet man eine Digitalkamera, so kann man durch die Fokussierung, die Größe der Blendenöffnung, die Verschlusszeit sowie die Brennweite des Objektivs die Qualität des Digitalisats beeinflussen oder bestimmte Bereiche der Vorlage besonders in den Blick nehmen.
Scanner sind Datenerfassungsgeräte, die die Vorlage mittels Licht nach bestimmten Rastern abtasten und digitalisieren. Dabei wird zwischen Flachbettscannern und Buchscannern unterschieden. Erstere sind vor allem für die Digitalisierung von einzelnen zweidimensionalen Objekten geeignet. Bücher können aufgrund der Buchbindung schlecht auf Flachbettscannern digitalisiert werden, da die Objekte dort mit der zu scannenden Seite flach auf der Glasplatte aufliegen müssen. Zudem kann so die Bindung zerstört werden. Daher verwendet man hier spezielle Buchscanner. Das Buch wird dabei aufgeschlagen auf die sogenannte Buchwippe gelegt und von oben abfotografiert. Glasplatten und andere Befestigungsmethoden sorgen dafür, dass die Seiten fixiert sind und sich nicht umblättern. Um bei wertvollen und empfindlichen Büchern die Bindung nicht zu zerstören, finden mittlerweile auch Scanner Verwendung, die eine Abtastung bei einem Öffnungswinkel von 45 Grad erlauben. Müssen ganze Bücher digitalisiert werden, kümmern sich Scan-Roboter um das automatische Umblättern und die Fixierung der Seiten.
Eine immer noch verwendete analoge Abbildungsmöglichkeit sind Mikroformen, wie Mikrofiche oder Mikrofilm. Hier wird eine Vorlage stark verkleinert auf Filmmaterial abgebildet. Mittels eines Lesegerätes kann diese Kopie vergrößert betrachtet werden. Die lange Haltbarkeit der Mikrofilme, die auf bis zu 500 Jahre geschätzt wird, macht sie zum idealen Speichermedium für Bibliotheken und Archive. Die Mikroformen können durch spezielle Geräte zudem digitalisiert werden, sodass man hier nicht das Original als Vorlage benötigt.
Die Metadaten
Zur Erschließung eines Digitalisats sind Metadaten von großer Wichtigkeit. Rehbein unterscheidet vier Typen von Metadaten. Deskriptive Metadaten beschreiben den Inhalt und sind vor allem zum Auffinden eines Digitalisats wichtig. Der Aufbau des Bildes oder Textes wird in den strukturellen Metadaten festgehalten, während die technischen Metadaten die Qualität des Objektes beurteilen. Die administrativen Metadaten geben Auskunft über die Nutzungsrechte. Insgesamt hat sich hier kein allgemeingültiger Standard durchsetzen können, sodass es eine große Zahl an Spezifikationen gibt, die auf die jeweiligen Fachgebiete zugeschnitten sind.
Digitale Texterfassung
Bei der Digitalisierung eines Textes müssen noch weitere Vorgaben beachtet werden. So muss hier nicht einfach nur das Druckbild digital erfasst werden, sondern auch der Text erkannt werden. Man bedient sich dafür zwei Methoden: Bei der manuellen Zeichenerfassung wird der Text per Hand abgetippt. Um Flüchtigkeitsfehler zu verhindern, wird ein Text dabei von mehreren Personen abgetippt und anschließend verglichen.
Beim zweiten Verfahren erfolgt wie bei der Bilddigitalisierung eine automatische digitale Abtastung der Vorlage als Rastergrafik, die als Optical Character Recognition bezeichnet wird. Mögliche Verzerrungen oder andere Bildstörungen, die die spätere Texterkennung stören könnten, sollten danach bei einer Vorverarbeitung behoben werden. Danach wird die Grafik binarisiert, d. h. jeder Bildpunkt wird entweder dem Hintergrund oder dem Text zugeordnet. Eine Analyse und Segmentierung der Vorlage filtert alle nicht zum Text gehörenden Bereiche wie Bilder aus der Texterkennung heraus. Die Textbereiche werden in Zeilen und Wortblöcke geordnet. Bei der anschließenden Zeichenerkennung werden die einzelnen Glyphen mit einem Modellzeichensatz verglichen und dementsprechend zugeordnet. In der Nachbearbeitung wird der Text mit Wörterbüchern verglichen, um mögliche Zeichen- und daraus resultierende Wortfehler zu beheben.
Damit ein solch digitalisierter Text für die wissenschaftliche Auswertung brauchbar ist, empfiehlt die DFG eine Textgenauigkeit von 99,95 %. Die Qualität einer Textdigitalisierung hängt dabei vom Zustand und der Textart der Vorlage ab. So ist das Erkennen von Handschriften wesentlich schwieriger als von Schreibmaschinen-, Computer- oder Buchdrucktexten.
Weitere Digitalisierungsformen
Dank moderner Techniken gibt es heute weitere Digitalisierungsformen. So ermöglichen 3D-Digitalisierungsverfahren eine gegenständliche Erfassung einer Vorlage. So können Informationen, die bei der zweidimensionalen Digitalisierung nur mittelbar als Metadaten erfasst werden können, direkt dargestellt werden. Daneben gibt es natürlich auch Digitalisierungen im nichtvisuellen Bereich. So werden z. B. akustische Analogvorlagen in digitale Formen umgewandelt.
Meine Erfahrungen mit Digitalisierungen und Digitalisaten
Als Student habe ich mit der Digitalisierung von Texten bereits Erfahrung gesammelt. Hierbei handelt es sich jedoch hauptsächlich um Sekundärliteratur, die ich für meine Forschungsarbeiten benötigt habe. Hier nutze ich sowohl Flachbett- als auch Buchscanner. Bilddigitalisierungen habe ich im Rahmen meiner Arbeit im Universitätsarchiv durchgeführt. Aufgrund des jungen Alters der Universität handelt es sich hierbei meist um Analogfotos oder Plakate. Als Digitalisierungswerkzeuge werden im Archiv sowohl ein Flachbettscanner als auch eine Digitalkamera genutzt.
Zur dauerhaften Nutzung halte ich Digitalisierungen für sehr wichtig, da sie die wissenschaftliche Arbeit stark erleichtern. So kann Quellmaterial geschont werden, da man für eine Untersuchung auf das digitale Abbild zurückgreifen kann. Gleichzeitig erleichtert eine Digitalisierung die Zugänglichkeit. So können Digitalisate ohne großen technischen oder finanziellen Aufwand vervielfältigt oder online bereitgestellt werden. Für mich liegt der Nachteil eines Digitalisats vor allem in den technischen Voraussetzungen, die erfüllt sein müssen, um auf das Abbild zuzugreifen. Ohne die entsprechende Hardware und Software ist eine Betrachtung und Auswertung des Dokuments nicht möglich. Zugleich müssen die digitalen Abbilder stets in die aktuellen Formate übertragen werden, um eine dauerhafte Nutzung zu gewährleisten. Ein großer Vorteil der Digitalisierung liegt vor allem auch in der Platzersparnis gegenüber Zettelkopien oder Büchern.